International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Dr.K.Anandakumar1, K.Rathipriya2, Dr.A.Bharathi3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
The large growth of Web has influenced the generation of huge e-learning resources. This work is focused to devise a personal recommendation system that will address the sparsity and cold-start problems and that will provide a have a more diverse recommendation list for each learner. Here Improved Neighborhood- based Collaborative filtering and Hybrid Genetic algorithm with Particle Swarm Optimization (PSO) method is implemented. These techniques are employed for improving the diversity, and the convergence towards the preferred solution taking into account the preferences of users. The results obtained from the experiments show that the proposed method outperforms current algorithms in terms of accuracy measures and can alleviate cold-start and sparsity problems and generate a more diverse recommendation list as well
Keywords |
| Personal learning Environments, Collaborative Filtering, Particle Swarm Optimization, Genetic Algorithm, learning behaviour. |
INTRODUCTION |
| In the education field , the learning behaviour of a learner is a criteria of greater importance since it greatly affects the learning process[1].Also, the process of learning is based on the teaching behaviour as well; if the teacher uses the same set of methods for teaching then the learner will not succeed [2]. Several learning processes are available; one of the learning process is based on mobile learning. Mobile learning process marked by flexibility, customization and collaboration [3 and 4]. One of the most important method is personalized recommendation and it is prosed by [5, 6], these methods implement the knowledge discovery methods for learners such as data mining and machine learning. These methods are used to discover the interests of users based on their activities and these activities are used to make the recommendation [7, 8]. Some of the example for e-learning sources for personalized recommendation is book recommendation in Amazon.com [9], movie recommendation in Netflix.com [10] and video recommendation in Tivo.com [11].Nowadays, there is a rapid development in web based education system. With the rapid development of online learning system, large numbers of e-learning sources are generated [12]. Some of the general procedures for personalized recommendation system consist of three steps; these steps are used to solve the problem in this system and are proposed in [13]. These steps are (i) record the user behaviour and generate a template for the behaviour (ii) Behaviour template should be maintained (iii) Generate recommendation information to users based on their behaviour template. |
| A Recommender system is to provide a personalized recommendation on the utility of a set of objects belonging to a given domain, starting from the information available about users and objects [22]. The given terms are used to define the recommendation problemC × I → R, in this expression C denotes the set of users of the system. I denote the recommender system and R denotes the totally ordered system [23] The paper is organized in this way: Section 2 introduces some background study about recommender systems; Section 3 describes the proposed methodology; Section 4 gives the result of the recommender system. Section 5 gives the conclusion of the research work. |
RELATED WORK |
| A Rule based recommendation system creates user behaviour rules through user history by association rule mining technology [14]. It is one of the simple recommendation system but it is hard to control the quality and quantity of the rules [15]. A Content-based recommendation is generated depending on the similarity differences between the content of resources and the preferences of the users [16]. Another approach for recommendation system is collaborative filtering studied in [17] and it is one of the most dominant methods. This system is not dependent on the content of the resources and the user’s new interests. The two types of collaborative filtering are memory based and model based algorithm [18]. |
| There are three ways to find out the student interaction and assessments to improve the learning [19]. The three steps are monitoring tools, metacognitive tools and guide systems. Monitoring tools are used to show or monitor the behaviour of the student to the student and the teacher based on their approach [20]. Metacognitive tools analyse the student behaviour based on desired outcome [21]. |
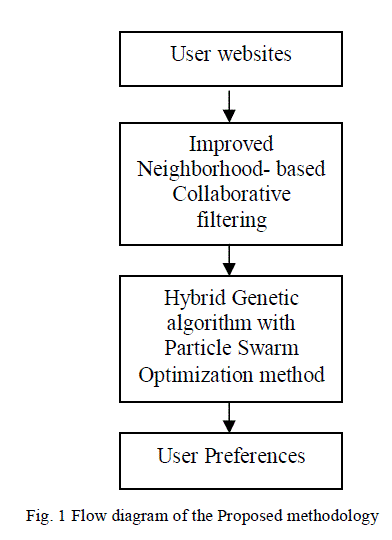 |
| The above figure (Fig. 1) represents the steps of the proposed methodology. Initially log data from User websites are given as input. Then Improved Neighbourhood based Collaborative Filtering Algorithm is used to classify similar users. After which Hybrid GA with PSO is used optimize the search process after which user preferences indicating final recommendations are generated. |
PROPOSED METHODOLOGY |
| A. Improved Neighborhood-based Collaborative Filtering |
| The most important approach to Collaborative filtering is the neighborhood-based approach. It is very popular and easy to implement. But however it has some drawbacks that are similarity function and the problem in previous neighborhood-based methods is that they do not account for interactions among neighbors. To overcome this limitation, improved Neighborhood-based collaborative filtering is used, the aim of which is to improvise the previous methods in order to remove the global effects. |
| This strategy is to estimate one “effect" at a time, in sequence. At each step, we use residuals from the previous step as the dependent variable for the current step. Consequently, after the first step, the refer to residuals, rather than raw ratings. For each of the effects mentioned above, our goal is to estimate either one parameter for each item or one parameter for each user. For the rest of this subsection, we describe our methods for estimating user specific parameters; the method for items is perfectly analogous. |
 |
| B. Hybrid GA with PSO |
| Many machine learning approaches have been applied by learning module developers, including inductive logic programming, decision tree, deductive reasoning, fuzzy logic, neural networks, and Genetic Algorithm. |
| The optimization problem is a difficult task to be carried out due to the huge search space. To overcome this setback, genetic algorithm is introduced to obtain the global optimum of a function. Genetic algorithm performs the optimization in four stages that are initialization, selection, crossover, and mutation [24]. The genetic algorithm starts with the initial solutions that are selected from a set of configurations in the search space called population using randomly generated solutions. By using a user fitness function, an intial solution of the each user can be examined. The second stage is the selection stage that which has the high score in the fitness is to be selected and reproduced by itself. The third stage is the crossover stage to produce the two chromosomes called as children produced from the couple of chromosomes called as parents. Crossover stage operates by swapping corresponding segments of a string representation of these parent and children. The final stage is the mutation stage which operates on a single chromosome. |
 |
| Particle Swarm Optimization (PSO) has a wide range of applications in many areas and it is one of the population based stochastic optimization techniques [25]. PSO is used to search the particles for optimal solution. Foe every iteration, update the two “best” values of each particle. pbest is the first best value; it represents the position vector of the best solution and it is achieved by this particle. The second best value is gbest which is the global best position and it identifies the best position found by the entire swarm until the iteration t. The particles update the velocity and position after finding these two best values and it is given by the equation below |
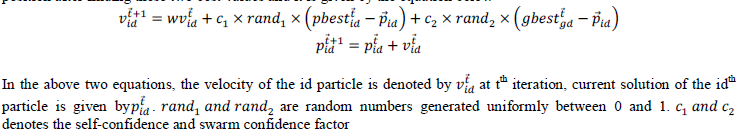 |
EXPERIMENTAL RESULTS |
| There are various types of datasets which can be recommended for this system. Here user’s opinion is collected from various users by creating a synthetic dataset and is taken for the process where it is implemented in java platform. The performance of this approach is measured using Decision support accuracy metrics assume the prediction process as a binary operation; either items are predicted (good) or not (bad). Precision and recall are the most popular metrics in this category. When referring to recommender systems, recall and precision can be defined as follows: |
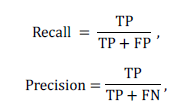 |
| Where, TP – True Positive, FP – False Positive and FN- False Negative. From the precision and recall the f-measure is calculated. |
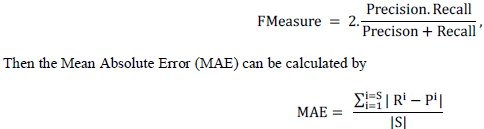 |
| where P is the predicted rating for resource i, R is the learner given rating for resource i, and S is the total number of the pair ratings R and R. |
| To make a prediction for a target user, here considered the number of rated items by the target user in training sets 5, 10, and 20. Then, we calculated the corresponding MAE using different algorithms. |
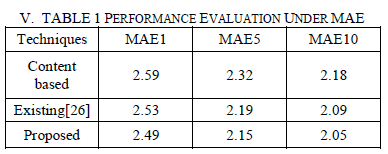 |
| The above table(TABLE 1) shows the performance comparison of the proposed system with the previous techniques .The performance evaluation is done by measuring the MAE.A decrease in the MAE value indicates an improved prediction accuracy of the recommendations generated. Here the proposed technique is compared with existing and content based system. |
CONCLUSION |
| Personalization is a factor which is to be given much importance as far as E-learning Recommender systems are concerned. The personalized recommendation system for e-learning applications is developed here by implementing Improved Neighborhood- based Collaborative filtering and Hybrid Genetic algorithm with Particle swarm optimization. The proposed system is evaluated using MAE and F- measure. The existing and proposed methods are compared and the results indicate that the proposed technique generates recommendation results with improved accuracy by minimizing the error rate. |
References |
|