International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Rangaswamy Y1, K B Raja2, Venugopal K R3, L M Patnaik4
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
The face is an efficient physiological biometric trait to authenticate a person without any cooperation. In this paper, we propose an Overlap Local Binary Pattern (OLBP) on Transform Domain based Face Recognition (OTDFR). The two sets of OLBP features are generated from transform domain. The first set of Overlap Local Binary Pattern (OLBP) features are extracted from Dual Tree Complex Wavelet Transform (DTCWT) coefficients of High frequency components of Discrete Wavelet Transforms (DWT). The second set of OLBP features are extracted from DTCWT coefficients. The final features are generated by concatenating features of set 1 and set 2. The test image features are compared with database features using Euclidian Distance (ED). It is observed that the percentage recognition rate is high in the case of proposed algorithm compared to existing algorithms
Keywords |
||||||||||||||||||||||||||||
| Biometrics, Face Image, DWT, DTCWT and OLBP. | ||||||||||||||||||||||||||||
INTRODUCTION |
||||||||||||||||||||||||||||
| The traditional authentication system to identify a person uses ID cards and passwords have drawbacks of breaching password and ID cards may be stolen or lost. The Biometrics is an alternative in identification of a person to traditional systems. The Biometrics is broadly classified into physiological and behavioral biometrics. The features of Physiological biometrics are constant over life period of human being and examples are fingerprint, iris, face, and retina. The characteristics of behavioral biometrics are vary over life time of a Person and examples are voice, signature and gait. Security applications such as access to office, computer systems, Mobile Phone, ATMs, Bank transactions, immobile property registration, intellectual property etc., require reliable authentication systems to confirm the identity of an individual.A General biometric system has three modules viz., (i) Enrolment Module: The biometric database of several persons with number of samples are acquired using data acquisition system. Each sample is pre-processed to remove noise, distortion and to extract Region of Interest (ROI). The features are extracted from each sample using either spatial domain or frequency domain technique. (ii) Test Module: The test biometric to be verified is acquired. The pre-processing is carried out on test image to extract ROI by removing noise and distortion. The features are extracted from the pre-processed sample using either spatial domain or frequency domain technique and (iii) Matching Module: The features of test biometric are compared with features of each biometric samples of an enrolment module using either distance formulae or classifiers to authenticate validity of a person. |
||||||||||||||||||||||||||||
| The biometric system operates in two modes such as (i) verification mode: performs an one-to-one comparison of a captured biometric image with a specific template stored in a biometric database in order to verify the individual and (ii) Identification mode: performs a one-to-many comparison against a biometric database to establish the identity of an unknown individual. The Physiological biometric traits have advantages over behavioural biometric traits in authentication of an human beings since (i) the features of physiological biometrics are constant throught life time, whereas the features of behavioural biometric traits are not constant and varies with mood circumstances and age of a person. (ii) The number of samples required to authenticate a person using physiological traits are less compare to behavioural biometric traits. The face images are considered to authenticate a person in the proposed algorithm since face is physiological biometric, the face images can be captured without the permission of a person and face images can also be captured with higher distances. |
||||||||||||||||||||||||||||
| Contribution: In this paper, OTDFR algorithm is proposed to authenticate a person efficiently. The two sets of texture features are extracted using DWT, DTCWT and OLBP. The final feature vector is concatenation of features set 1 and features set 2. The ED is used to compare features between test and database images to identify a person. |
||||||||||||||||||||||||||||
| Organization: section I gives brief introduction of Biometrics. The literature survey of existing techniques described in section II. In section III transformations are discussed. The proposed model is described in section IV. In section V algorithm is given. The performance analysis is discussed in section VI. The conclusions are given in section VII. |
||||||||||||||||||||||||||||
LITERATURE SURVEY |
||||||||||||||||||||||||||||
| Taskeed Jabid et al., [1] presented a Local Directional Pattern (LDP) to recognize human face. A LDP feature is obtained by computing the edge response values in all eight directions at each pixel position and generating a code from the relative strength magnitude. Each face is represented as a collection of LDP codes for the recognition process. The Chi-Square dissimilarity measure is used for comparison. Miao Cheng et al., [2] proposed a face recognition method using Local Discriminant Subspace Embedding (LDSE) to extract discriminative features. The Incremental LDSE (ILDSE) is proposed to learn the local discriminant subspace with the newly inserted data, which applies incremental learning extension to the batch LDSE algorithm by employing the idea of singular value decomposition updating algorithm. The KNN classifier with Euclidean distance metric is used for classification. Xi Li et al., [3] propose a multiscale heat kernel based face representation; it performs well in characterizing the topological structural information of face appearance. The local binary pattern descriptor is incorporated into the multiscale heat kernel face representation for the purpose of capturing texture information of face appearance. The support vector machine classifier is used for face classification. Seyed Mohammad et al., [4] proposed an approach for face recognition by composing Symlet decomposition, Fisherface algorithm and Choquet Fuzzy Integral. The Symlet Wavelet is used to transform an image into four sub-images such as approximate, horizontal, vertical and diagonal partial images respectively to extract intrinsic facial features. The Fisherface method which is composed of PCA and LDA is used to make system not sensitive to intensive light variations and facial expression and gesture. The Sugeno and Choquet fuzzy integral are used as classifiers. |
||||||||||||||||||||||||||||
| Hamit Soyel et al., [5] implemented a binary non sub sampled contourlet transform based illumination face representation. Faces are transformed into multi-scale and multi-directional contour information where the intrinsic geometrical structures are used for characterizing facial texture. The matching is done using nearest neighbour classifier based on Euclidean distance. Atefe Assadi and Alireza Behrad [6] discussed an algorithm which is the combination of texture and 3D information to overcome the problem of pose variation and illumination change for face recognition. The intensity of image is used to extract features and find probable face matches in the face database using feature matching algorithm. The 3D information are normalized used for pose invariant face recognition.Di Huang et al., [7] proposed an effective approach to 3-D face recognition using geometric facial representation and local feature hybrid matching. The preprocessing includes spike removal and hole filling. The 3-D shape based geometric facial descriptions consisting small local area features called facial depth maps are extracted by multiscale extended Local Binary Patterns (eLBP). SIFT-based hybrid matching, which combines local and holistic analysis, is used for comparing two face images. The proposed method is evaluated in 3-D face recognition and verification. Ping-Han Lee et al., [8] proposed orientated local histogram equalization (OLHE) technique, that compensates illumination by encoding more information on the edge orientations, and argued that edge orientation is useful for face recognition. |
||||||||||||||||||||||||||||
| Three OLHE feature combination methods are proposed for face recognition: one encoded most edge orientations; one was more compact with good edge-preserving capability, the performed well when extreme lighting conditions occur. They also showed that LBP is a special case of OLHE and OLHE is more effective than LBP for face recognition. The computational complexity of OLHE is less compared to state-of-the-art algorithms such as logarithm total variation model (LTV) that involves additional chain of preprocessing or total variation quotient image model (TVQI) that requires solving a variation problem. |
||||||||||||||||||||||||||||
| Vishal M Patel et al., [9] proposed an algorithm to perform face recognition across varying illumination and pose based on learning small sized class specific dictionaries. This method consists of two main stages. In the first stage, given training samples from each class, class specific dictionaries are trained with some fixed number of atoms (elements of a dictionary). In the second stage, test face image is projected onto a span of the atoms in each learned dictionary. The residual vectors are then used for classification. Raghuraman Gopalan et al., [10] proposed that the subspace resulting from convolution of an image with a complete set of ortho normal basis functions of a pre-specified maximum size and show that the corresponding subspace created from a clean image and its blurred versions are equal under the ideal case of zero noise and some assumptions on the properties of blur kernels, and it can account for more general class of blur unlike other invariants. Chan et al., [11] proposed face recognition using blur-robust face image descriptor based on Local Phase Quantization (LPQ) and extend it to a Multiscale Local Phase Quantization framework (MLPQ) to increase its effectiveness. The MLPQ descriptor is computed regionally by adopting a component-based framework to maximize the insensitivity to misalignment. The regional features are combined using kernel fusion. The proposed MLPQ representation is combined with the Multiscale Local Binary Pattern (MLBP) descriptor using kernel fusion to increase insensitivity to illumination. Kernel Discriminant Analysis (KDA) of the combined features extracts discriminative information for face recognition. Two geometric normalizations are used to generate and combine multiple scores from different face image scales to further enhance the accuracy. Jun et al., [12] proposed face recognition based on Local Gradient Pattern (LGP) and Binary Histogram of Oriented Gradients (BHOG). LGP assigns one if the neighboring gradient of a given pixel is greater than the average of its eight neighboring gradients, and zero otherwise, which makes the local intensity variations along the edge components robust. BHOG assigns one if the histogram bin has a higher value than the average value of the total histogram bins, and zero otherwise. The Support Vector Machine (SVM) is used for classification. Zhen Lei et al.,[13] described learning based discriminant face descriptor (DFD) for face recognition. A discriminant image filter learning method and Soft Sampling Matrix (SSM) are learned to differentiate the importance of each neighbor and to extract the discriminant face features. The discriminant image filter and the optimal soft sampling learning are incorporated to obtain a Discriminant Face Descriptor (DFD). Adin Ramirez Rivera et al., [14] proposed face recognition using Local Directional Number (LDN) pattern. LDN encodes the structure of a local neighborhood by analyzing its directional information. |
||||||||||||||||||||||||||||
| Muhammad Zafar Iqbal et al., [15] proposed Resolution Enhancement method based on DT-CWT and an NLM filter. DT-CWT is used to overcome the shift variant and artifacts of DWT. NLM filtering is used to overcome the artifacts generated by DT-CWT and to enhance the performance of the proposed technique in terms of MSE, PSNR, and Qindex. Simulation results highlight the superior performance of proposed techniques. |
||||||||||||||||||||||||||||
| Massimo Fierro et al., [16] described a Noise Reduction technique to enhance image based on Dual-Tree Complex Wavelet Transform coefficient Shrinkage. The DTWCT allows for distinction of data directionality in the transform space. For each level of the transform, the standard deviation of the non- enhanced image coefficients is computed across the six orientations of the DTWCT, and then it is normalized. The result is a map of the directional structures present in the non-enhanced image. Said map is then used to shrink the coefficients of the enhanced image. |
||||||||||||||||||||||||||||
BACKGROUND |
||||||||||||||||||||||||||||
| In this section, the DWT, DT-CWT and OLBP are discussed. | ||||||||||||||||||||||||||||
| A Discrete Wavelet Transform (DWT) | ||||||||||||||||||||||||||||
| The wavelet transform [17] uses multi resolution techniques to analyze different frequencies with different resolutions. The image is decomposed into different frequency range using mother wavelet and scaling function. In DWT an image ?? ??, ?? is filtered along the rows followed by filtering along columns with decimation by two is as shown in figure1. In row processing the image is decomposed into two parts using Low Pass Filter (LPF) and High Pass Filter (HPF) with decimation by 2. In column processing the outputs of LPF and HPF are further decomposed into LPF and HPF followed by decimation by 2 to derive final row column processing of first level wavelet decomposition. |
||||||||||||||||||||||||||||
| This operation decomposes frequency components into two parts viz., low frequency and high frequency components. The image is decomposed into four bands in such a way that one band belongs to low frequency component i.e., approximation band (LL) and three band belongs to high frequency components viz., vertical band (LH), horizontal band (HL) and diagonal band (HH) as shown in Figure 1. |
||||||||||||||||||||||||||||
| The dimension of each sub band is half of the original image. The LH and HL sub bands are oriented vertically and horizontally respectively where as HH sub band is oriented diagonally with 45°and -45°. |
||||||||||||||||||||||||||||
| The advantages of DWT are: (i) It gives information about both time and frequency of the signal. (ii) Reduces redundancy. (iii) Reduces computational time. (iv)Transform of a non-stationary signal is obtained efficiently. (v) Reduces size without losing much of resolution. The disadvantages of DWT are (i) Oscillations: Since wavelets are band pass functions, the energy of wavelet coefficients tends to oscillate between positive and negative around singularities (jumps and spikes) this makes complications in wavelet based processing and singularity extraction.(ii) Shift Variance: the wavelet coefficients of a signal ?? ?? are very sensitive to shifts of the signal i.e., for a small shift in the signal affects the wavelet coefficients which oscillates around the singularity and the energy of the wavelet coefficient at any fixed scale j is not constant and complicates the wavelet domain processing. (iii) Aliasing: Aliasing occurs in DWT either the samples of wavelet coefficients are widely spaced or wavelet coefficients are obtained from discrete time down sampling operation on the non-ideal low pass and high pass filters. If the wavelet and scaling coefficients are not changed then inverse DWT cancel this aliasing. (iv) Lack of directionality: The standard tensor product construction of M-Dimensional wavelets produces a checkerboard pattern that is simultaneously oriented in several directions. This complicates modeling and processing of geometric image features like ridges and edges. |
||||||||||||||||||||||||||||
| B. Dual Tree Complex Wavelet Transform (DT-CWT) | ||||||||||||||||||||||||||||
| It is a recent enhancement technique to DWT with additional properties and changes. It is an effective method for implementing an analytical wavelet transform, first introduced by Kingsbury [18] in 1998. Generating complex coefficients by DTCWT introduces limited redundancy and allows the transform to provide shift invariance and directional selectivity of filters. The DTCWT employs two real DWTs; the first DWT can be thought as the real part of the complex transform while the second DWT can be thought as the imaginary part of the complex transform. The two levels DT-CWT implementation is shown in Figure 2. The two real wavelet transforms use two different sets of filters, with each satisfying the perfect reconstruction conditions. The two sets of filters are jointly designed so that the overall transform is approximately analytic. Let ?0(??) and ?1(??)denote the low-pass and high-pass filter pair for the upper filter-bank, and let ??0(??) and ??1(??)denote the low-pass and high-pass filter pair for the lower filter-bank. The two real wavelets associated with each of the two real wavelet transforms will be upper wavelet denoted as ??? (??)and lower wavelet denoted as ????(??). The ????(??) is the Hilbert Transform of ??? (??). The DTCWT ??(??) = ??? (??) + ?????? ?? is approximately analytic and results in perfect reconstruction. |
||||||||||||||||||||||||||||
| To invert the transform, the real part and the imaginary parts are inverted, to obtain two real signals. These two real signals are then averaged to obtain the final output. The original signal ?? (??)can also be recovered from either the real part or an imaginary part alone however; such inverse DTCWTs do not capture all the advantages of an analytic wavelet transform. When the DTCWT is applied to a real signal, the output of the upper and lower filter banks will be the real and imaginary parts of the complex coefficients. However, if the DTCWT is applied to a complex signal, then the output of both the upper and lower filter banks will be complex. For a real N-point signal 2N complex coefficients are obtained, but N of these coefficients are the complex conjugates of the other N coefficients. |
||||||||||||||||||||||||||||
| C. Overlap Local Binary Pattern (OLBP) | ||||||||||||||||||||||||||||
| The original LBP operator was introduced by Ojala et al., [19] a non parametric algorithm to describe texture in 2-D images. The properties of LBP features are its tolerance to illumination variations and computational simplicity hence it is widely used in 2-D face recognition. The LBP operator labels each pixel of a given 2-D image by a binary using thresholding in a 3x3 neighborhood. If the values of the neighboring pixels are greater than that of the central pixel, their corresponding binary bits are assigned to 1; otherwise they are assigned to 0. A binary number is formed with all the eight binary bits, and the resulting decimal value is used for labeling centre pixel of 3x3 matrix. |
||||||||||||||||||||||||||||
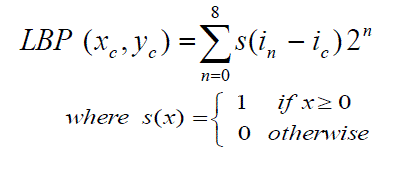 |
||||||||||||||||||||||||||||
| Figure 3 illustrates the LBP operator by a simple example. For any given pixel at (???? , ????) the LBP decimal value is derived by using the Equation (1) where n denotes the eight neighbors of the central pixel, ????and n i are the gray level values of the central pixel and its surrounding pixels respectively. According to Equation (1), the LBP code is invariant to monotonic gray-scale transformations, preserving their pixel orders in local neighborhoods. |
||||||||||||||||||||||||||||
| In case of overlapping LBP, the next adjacent pixel to the center pixel of first LBP operator is considered as the threshold for the next LBP operator i.e., if we consider (???? , ????) as the center pixel (threshold) for first LBP operator, then the next adjacent pixel i.e., ????+1, ????+1 is considered as the threshold for next adjacent LBP operator. So that if there is any small variation in the texture or illumination variation of an image that can be obtained. |
||||||||||||||||||||||||||||
PROPOSED MODEL |
||||||||||||||||||||||||||||
| The DWT, DTCWT and overlapping LBP techniques are used to generate features of face images to identify a person correctly with less error rates. The block diagram of the proposed model is shown in the Figure 4. |
||||||||||||||||||||||||||||
| A. Face Databases | ||||||||||||||||||||||||||||
| The proposed algorithm is tested using some of the universally available databases such as ORL, JAFFE, Indian male, Indian females and L-Speck databases. |
||||||||||||||||||||||||||||
| 1) ORL database: The ORL face database [20] has of forty persons with ten images per person. The ten different images of a same person are taken at different times by varying lightning, facial expression (which includes opening/closing of eyes and smiling/not smiling), facial details (glass\no glass).The database is created by considering first twenty persons out of forty persons and first nine images per person are considered to create database which leads to one eighty images in the database and tenth image from first twenty persons are taken as test image to compute FRR and TSR. The remaining twenty persons out of forty are considered as out of database to compute FAR. The sample images of ORL database are shown in Figure 5. |
||||||||||||||||||||||||||||
| 2) JAFFE database: The JAFEE face database [21] shown in Figure 6 consists of ten persons with approximately twenty images per person. The different images are taken based on emotional facial expressions such as happy, neutral, angry, disgust, fear, sad and surprise. The database is created by considering first five persons out of ten persons and first ten images per person are considered to create database which leads to fifty images in the database and fourteenth image from first five persons are taken as test image to compute FRR and TSR. The remaining five persons out of ten are considered as out of database to compute FAR. |
||||||||||||||||||||||||||||
| 3) Indian male: The Indian male face database [22] shown in Figure7 has twenty persons with approximately eleven images per person. The images were taken in homogeneous background with an upright and frontal position. The eleven different images include facial orientations such as looking front, looking left, looking right, looking up, looking up towards left, looking up towards right, looking down, with emotions neutral, smile, laughter, sad/disgust. The database is created by considering first ten persons out of twenty persons with first eight images per persons are considered to create database which leads to eighty images in the database and ninth image from first ten persons are taken as test image to compute FRR and TSR. The remaining ten persons out of twenty persons are considered as out of database to compute FAR. |
||||||||||||||||||||||||||||
| 4) Indian female: The Indian females face database [22] shown in Figure 8 consists of twenty two persons with approximately eleven images per person. The variations in pose and expressions are same as Indian male face database. The database is created by considering first eleven persons out of twenty two persons with first eight images per persons are considered to create database which leads to eighty eight images in the database and ninth image from first eleven persons are taken as test image to compute FRR and TSR. The remaining eleven persons out of twenty two persons are considered as out of database to compute FAR. |
||||||||||||||||||||||||||||
| 5) L-Speacek: The L-speacek face database [23] shown in Figure 9 consists of one hundred twenty persons with nineteen images per person. The database is created by considering first sixty persons out of one hundred and twenty persons and first ten images per person are considered to create database which leads to six hundred images and fourteenth image from first sixty persons are taken as test image to compute FRR and TSR. The remaining sixty persons out of one hundred twenty persons are considered as out of database to compute FAR. |
||||||||||||||||||||||||||||
| B. Preprocessing. | ||||||||||||||||||||||||||||
| The color images of face are converted into gray scale images. The face images have different sizes hence images are resized to uniform dimensions. |
||||||||||||||||||||||||||||
| C. Feature Extraction | ||||||||||||||||||||||||||||
| The OLBP is used on DTCWT coefficients, derived from DWT to generate detailed high frequency features of an image which forms Feature set one. The second set of features is obtained by applying OLBP on DT-CWT coefficients derived from preprocessed face image. The final feature set is obtained from fusion of feature set 1 and set2. |
||||||||||||||||||||||||||||
| 1) Feature set1: High frequency Texture features of an image: Texture Feature of DTCWT coefficients derived from only high frequency components of DWT are considered as Feature set 1.The two level DWT is applied on preprocessed image and considered three detailed sub bands of first level and three detailed sub bands of second level i.e., totally six detailed sub bands corresponding to high frequencies of an image. The DTCWT is applied on high frequency components of an image to derive twelve high frequency and four low frequency sub bands. The OLBP is applied on DTCWT coefficient matrix to capture micro level information of each coefficient. |
||||||||||||||||||||||||||||
| (i) DWT Features: The two level DWT is applied on preprocessed face images of size 128x128. The first level high frequency sub bands such as LH1, HL1 and HH1, each of size 64x64 matrix is converted into vector size of 4096 coefficients. |
||||||||||||||||||||||||||||
| The all three sub band vector coefficients are concatenated to generate first level 12288 coefficients. The second level DWT is applied and considered high frequency sub bands such as LH2, HL2 and HH2 each of size 32x32.The matrix coefficient values of each sub band are converted into vector with 1024 coefficients. Three sub band coefficients of second level are concatenated to generate 3072 coefficients. The final DWT feature coefficients are derived by concatenating level1 and level2 high frequency vectors to generate 15360 coefficients in a single vector. The single vector is converted into matrix of size 128x120. To use DT-CWT on DWT coefficient matrix, the obtained DWT matrix of size 128x120 is reshaped to a size of 128x128. The matrix 128x128 has only high frequency coefficients of DWT. |
||||||||||||||||||||||||||||
| (ii) DT-CWT Features: Three-Level DT-CWT is applied on 128x128 DWT matrix. Each level of DT-CWT has 16 sub bands with four low frequency sub bands and 12 high frequency sub bands as shown in Figure 10 |
||||||||||||||||||||||||||||
| The size of each high frequency sub band in third level is 16 x16 and is converted into vector of size 256 coefficients. The three high frequency sub-band vector coefficients of each tree are concatenated to generate 768 coefficients. The vector m5, m6, m7 and m8 are corresponding to high frequency coefficients of Tree a, Tree b, Tree c and Tree d respectively. The absolute magnitude values are calculated using real and imaginary trees using Equations 2 and 3. |
||||||||||||||||||||||||||||
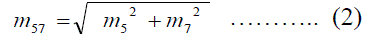 |
||||||||||||||||||||||||||||
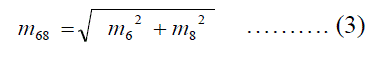 |
||||||||||||||||||||||||||||
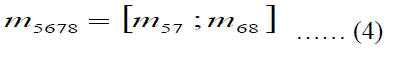 |
||||||||||||||||||||||||||||
| The magnitude vector coefficients of m57 and m68 are concatenated using Equation 4 to generate 1536 final high frequency coefficient vector m5678.The four low frequency bands each of size 16x16 is converted into single vector of size 256 coefficients. The four low frequency sub band vector coefficients are concatenated to generate final low frequency vector of size 1024 coefficients. The total high frequency and low frequency coefficients are concatenated to generate final coefficients of third level DT-CWT of size 2560 coefficients. The final DT-CWT coefficient vector is converted into matrix of size 32x80. |
||||||||||||||||||||||||||||
| (iii) OLBP Texture Features: The zeros are padded on all four sides of 32x80 DTCWT matrix to convert into 34x82 matrix size to consider information of boundary coefficients. OLBP is applied on DT-CWT coefficient matrix of size 34x82. The 3x3 matrix is considered in 34x82 DT-CWT coefficient matrix. The value of centre coefficient is considered as reference. |
||||||||||||||||||||||||||||
| The adjacent to centre coefficient values are compared with reference coefficient value , if adjacent pixel coefficient value is greater than reference value then coefficient value is assigned with binary value of 1 else assigned 0. The binary values of eight adjacent coefficients are converted into decimal value which is considered as OLBP feature of centre coefficient. Similarly the decimal values for remaining 3x3 overlapping matrix are computed to generate feature set1 with 2560 coefficients. |
||||||||||||||||||||||||||||
| 2) Feature set 2: Texture Features of all frequency sub bands of DTCWT: The texture features of all sub bands of DTCWT are considered. (i) DTCWT Features: The three level DT-CWT is applied on preprocessed face image size of 128x128 to generate twelve high and four low frequency sub bands of each size 16x16. The high frequency magnitude vector coefficients of size 1536 are generated using Equation 4.The four low frequency sub band vector coefficients are concatenated to generate 1024 low frequency coefficients. The high and low frequency coefficients are concatenated to generate 2560 DTCWT feature coefficients. The DTCWT coefficient vector is converted into matrix of size 32x80.(ii) OLBP Texture features: The texture features of DTCWT coefficients are generated using OLBP technique. The zeros are padded on all four sides of 32x80 DTCWT matrix to convert into 34x82 matrix size to compute texture features of every DTCWT coefficients. The feature set 2 has 2560 OLBP texture features. |
||||||||||||||||||||||||||||
| 3) Final Features: The feature set1 coefficients are concatenated with feature set2 to generate final features of size 5120 coefficients. |
||||||||||||||||||||||||||||
| 4) Test Section: Any one image of a person is considered as a test image. The preprocessing and feature extraction is same as enrolment section. |
||||||||||||||||||||||||||||
| D. Matching | ||||||||||||||||||||||||||||
| The features of test image are compared with images in the database using Euclidian Distance(ED) given in Equation 5. |
||||||||||||||||||||||||||||
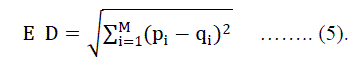 |
||||||||||||||||||||||||||||
| Where, M= No of coefficients in a vector. | ||||||||||||||||||||||||||||
| pi= coefficient values of vectors in database. | ||||||||||||||||||||||||||||
| qi= coefficient values of vector in test image. | ||||||||||||||||||||||||||||
| A. Problem Definition | ||||||||||||||||||||||||||||
| The face recognition biometric system is developed by generating texture features from DWT and DTCWT. The objectives are |
||||||||||||||||||||||||||||
| i) To increase TSR. | ||||||||||||||||||||||||||||
| (ii) To decrease FRR, FAR and EER. | ||||||||||||||||||||||||||||
| The efficient proposed face identification algorithms using DWT, DTCWT and OLBP techniques is given in Table I. | ||||||||||||||||||||||||||||
| In this section the definitions of performance parameters and performance analysis of proposed model are discussed. | ||||||||||||||||||||||||||||
| A. Definitions of Performance Parameters | ||||||||||||||||||||||||||||
| 1) False Acceptance Rate (FAR): The number of unauthorized persons is accepted as authorized persons. It is the ratio of the number of unauthorized persons accepted to the total number of persons in the outside database and given in Equation 6. |
||||||||||||||||||||||||||||
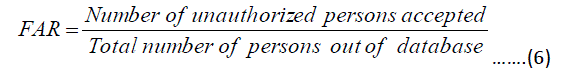 |
||||||||||||||||||||||||||||
| 2) False Rejection Rate (FRR): The number of authorized persons rejected as unauthorized person. It is the ratio of number of authorized persons rejected to the total no of persons in the database as given in Equation 7. |
||||||||||||||||||||||||||||
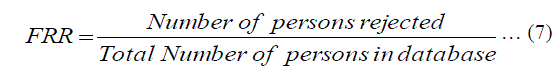 |
||||||||||||||||||||||||||||
| 3) True Success Rate (TSR): The number of authorized persons recognized correctly in the database. It is the ratio of number of persons correctly matched to the total no of persons in the database and is given in Equation8. |
||||||||||||||||||||||||||||
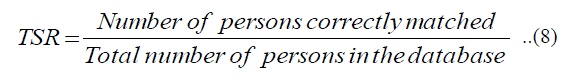 |
||||||||||||||||||||||||||||
| 4) Equal Error Rate (EER): It is the measure of trade-off between FAR and FRR and is given in Equation 9. | ||||||||||||||||||||||||||||
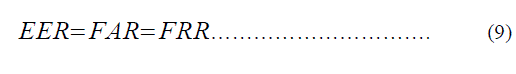 |
||||||||||||||||||||||||||||
| B. Analysis of Performance Parameters | ||||||||||||||||||||||||||||
| The Performance Parameters such as FRR, FAR, EER and TSR for different face databases viz., ORL, JAFFE, Indian male, Indian female and L-spacek are discussed in detail for the proposed model. |
||||||||||||||||||||||||||||
| 1) Analysis with ORL face database: The Percentage variations of FRR, FAR and TSR with threshold for ORL database is given in Table II. The Percentage values of FAR and TSR increases from 0 to maximum value as threshold value increases. The Percentage values of FRR decreases from 100 to 0 as threshold value increases. The maximum success rate of the proposed algorithm for ORL database is 95% from threshold value 0.067.The variations of Percentage values of FAR and FRR with threshold for ORL database is shown in Figure 11. The values of FRR and FAR decreases and increases respectively as threshold value increases. It is observed that the value of EER is zero for the threshold value of 0.068 with Percentage TSR is 95. |
||||||||||||||||||||||||||||
| 2) Analysis with JAFFE face database: The Percentage variations of FRR, FAR and TSR with threshold for JAFFE database is given in Table III. The Percentage values of FAR and TSR increases from 0 to maximum value as threshold value increases. The Percentage values of FRR decreases from 100 to 0 as threshold value increases. The maximum success rate of the proposed algorithm for JAFEE database is 100%. The Percentage values of FAR and FRR with threshold for JAFEE database is shown in Figure 12. The values of FRR and FAR decreases and increases respectively as threshold value increases. It is observed that the value of EER is zero for the threshold value of 0.06 with Percentage TSR is 100.The value of TSR is high in the case of JAFFE database compared to ORL database since JAFFE database face samples are less variations in face expressions. |
||||||||||||||||||||||||||||
| 3) Aanalysis with Indian male face database: The Percentage variations of FRR, FAR and TSR with threshold for Indian male database are given in Table IV. The Percentage values of FAR and TSR increases from 0 to maximum value as threshold value increases. The Percentage values of FRR decreases from 100 to 0 as threshold value increases. The maximum success rate of the proposed algorithm for Indian male database is 90%.The Percentage values of FAR and FRR with threshold for Indian male database is shown in Figure 13. The values of FRR and FAR decreases and increases respectively as threshold value increases. It is observed that the value of EER is ten for the threshold value of 0.0672 with Percentage TSR is 80. The error rate EER is high in the case of Indian males face database compared to ORL and JAFFE database since the variations in the angles are more. |
||||||||||||||||||||||||||||
| 4) Analysis with Indian female face database: The Percentage values of FAR and TSR increases from 0 to maximum value as threshold value increases The Percentage variations of FRR, FAR and TSR with threshold for Indian female database is given in Table V. The Percentage values of FRR decreases from 100 to 0 as threshold value increases. The maximum success rate of the proposed algorithm for Indian female database is 100%.The Percentage values of FAR and FRR with threshold for Indian female database is shown in Figure 14. The values of FRR and FAR decreases and increases respectively as threshold value increases. It is observed that the value of EER is 18.18 for the threshold value of 0.0644 with percentage TSR 81.The error rate using Indian females Face database is high compared to ORL, JAFFE and Indian males face database since pose variations are high. |
||||||||||||||||||||||||||||
| 5) Analysis with L-spacek Face database: The Percentage variations of FRR, FAR and TSR with threshold for Lspacek database is given in Table VI. The values of FAR and TSR increases from 0 to maximum value as threshold value increases. The Percentage values of FRR decreases from 100 to 0 as threshold value increases. The maximum success rate of the proposed algorithm for L-spacek database is 100%.The Percentage values of FAR and FRR with threshold for L-spacek database is shown in Figure 15. The values of FRR and FAR decreases and increases respectively as threshold value increases. It is observed that the value of EER is zero for threshold value of 0.058 with Percentage TSR is 100. The error rate is zero and success rate is 100% using Lspacek face database in the proposed algorithm since the variations in the L-spacek database are less compared to ORL , JAFFE, Indian males and Indian females database. |
||||||||||||||||||||||||||||
| 6) The Comparison of EER and TSR values for different face databases: The percentage values of EER and TSR for the proposed model using ORL, JAFFE, Indian males, Indian females and L-spacek databases are tabulated in Table VII. The percentage EER value is zero with ORL, JAFFE and L-spacek database since the variations in the face image samples are less. The percentage EER values are non-zero for Indian males and Indian females face databases as variations in the face samples are more. The success rate in the proposed method using ORL, JAFFE and L-spacek has high values ie. 95% to 100% as compared to around 80% success rate using Indian males and Indian females databases. |
||||||||||||||||||||||||||||
| 7) The Percentage TSR Comparison of Proposed algorithm with existing algorithms: The Performance of Proposed method is compared with the existing algorithms using DWT [24], PCA+2DPCA [25] and Gabor filter +DWT+PCA [26] in terms of TSR for ORL database which is given in Table VIII. The Percentage TSR value is high in the case of proposed method compared to existing algorithms because of following reasons: (i) the first set of texture features are extracted using high frequency sub bands of DWT, DTCWT and OLBP on preprocessed face images. (ii) The second set of texture features are obtained by applying DTCWT and OLBP on preprocessed face images to extract features of all frequency components of an image.(iii) The OLBP texture features from high frequency and all frequency components of an image to capture micro level information of each coefficients in a transform domain (iv)The final effective features are derived by concatening features set1 and features set2. |
||||||||||||||||||||||||||||
CONCLUSIONS |
||||||||||||||||||||||||||||
| In this paper OTDFR algorithm is proposed to identify a person efficiently. The two sets of texture features using OLBP are generated. The micro level texture features are extracted from DTCWT coefficients of high frequency components of DWT for detailed information of an image in feature set 1. The significant texture features are extracted from DTCWT coefficients in feature set 2. The final feature set is obtained by concatenating feature set 1 and set 2.The features of test image are compared with database image using ED. It is observed that percentage recognition rate is high in the case of proposed algorithm compared to existing algorithms. In future texture features of spatial domain and transform domain are fused. |
||||||||||||||||||||||||||||
ACKNOWLEDGMENT |
||||||||||||||||||||||||||||
| We thank management of Alpha College of Engineering, Bangalore and Jawaharlal Nehru Technological University,Anantapur, for their support in research. |
||||||||||||||||||||||||||||
Tables at a glance |
||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||
Figures at a glance |
||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||
References |
||||||||||||||||||||||||||||
|












