International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
R.S.Venkatesh1, P.K.Reejeesh1, Prof.S.Balamurugan1, S.Charanyaa2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
This paper reviews methods developed for anonymizing data from 1998 to 2000 . Publishing microdata such as census or patient data for extensive research and other purposes is an important problem area being focused by government agencies and other social associations. The traditional approach identified through literature survey reveals that the approach of eliminating uniquely identifying fields such as social security number from microdata, still results in disclosure of sensitive data, k-anonymization optimization algorithm ,seems to be promising and powerful in certain cases ,still carrying the restrictions that optimized k-anonymity are NP-hard, thereby leading to severe computational challenges. k-anonimity faces the problem of homogeneity attack and background knowledge attack . The notion of ldiversity proposed in the literature to address this issue also poses a number of constraints , as it proved to be inefficient to prevent attribute disclosure (skewness attack and similarity attack), l-diversity is difficult to achieve and may not provide sufficient privacy protection against sensitive attribute across equivalence class can substantially improve the privacy as against information disclosure limitation techniques such as sampling cell suppression rounding and data swapping and pertubertation. This paper aims to discuss efficient anonymization approach that requires partitioning of microdata equivalence classes and by minimizing closeness by kernel smoothing and determining ether move distances by controlling the distribution pattern of sensitive attribute in a microdata and also maintaining diversity.
Keywords |
| Data Anonymization, Microdata, k-anonymity, Identity Disclosure, Attribute Disclosure, Diversity |
INTRODUCTION |
| Need for publishing sensitive data to public has grown extravagantly during recent years. Though publishing demands its need there is a restriction that published social network data should not disclose private information of individuals. Hence protecting privacy of individuals and ensuring utility of social networ data as well becomes a challenging and interesting research topic. Considering a graphical model [35] where the vertex indicates a sensitive label algorithms could be developed to publish the non-tabular data without compromising privacy of individuals. Though the data is represented in graphical model after KDLD sequence generation [35] the data is susceptible to several attacks such as homogeneity attack, background knowledge attack, similarity attacks and many more. In this paper we have made an investigation on the attacks and possible solutions proposed in literature and efficiency of the same. |
A SECURITY ARCHITECTURE FOR COMPUTATIONAL GRIDS |
| A security architecture and its associated security policy’s along with different security requirements are revealed in this paper. Distributed supercomputing, teleimmersion, computer-enhanced instruments, distributed data mining are the functions related to computational grids or distributed computing. |
| Any distributed system has some special features like scalability, performance and heterogeneity. But an added credit to computational grids is that it solves all the security issues found in prior an existing security mechanisms. |
| The distributed security system offers |
| 1.In-detail observation of security issues. |
| 2. Brief explanation of security policy. |
| 3. Provides suitable solutions to some particular security threats. |
| 4. Offers a security architecture to execute security policy. |
| Some computing grids posses unique characteristics like |
| 1. Usage of dynamic resource pool. |
| 2. Every computational process requires an initial and termination step to be included. |
| 3. Processes communications through unicast and multicast. |
| 4. Different techniques of authentication and authorization are needed for resources. |
| 5. A single user may have different accounts in different locations. |
| The major pitfall that we see in all computations is that we have to identify an appropriate solution to improve security. |
| Any grid system needs the following requirements to be satisfied: |
| 1. A proper authentication process should be used to verify each and every user who tries to compute. |
| 2. Access control mechanisms should be implemented without modification. |
| These security requirements should be properly satisfied by building a security architecture. This architecture should satisfy certain conditions such as: |
| 1. Single-sign on |
| 2. Protection of credentials |
| 3. Interpretability of local security solution |
| 4. Exportability. |
| 5. Uniform credentials infrastructure |
| 6. Support for secure group communication |
| 7. Support for multiple implementations. |
| Security policy derives a set of rules that defines the relationship between a subject and an object. A subject generally refers to users. Passwords and certificates are some credentials used for verifying a subject. A resource that is protected using security policy is called as object. A trust domain consists of both subject and objects. The security policies used in computing grids are listed below. |
| 1. Computing grids must hold multiple trust domains. |
| 2. Single trust domain makes use of only local security policies. |
| 3. A trust domain is plotted to local subjects from global subjects. |
| 4. Mutual authentication is needed for performing operations among entities in a trust domain. |
| 5. Access control decisions are based on local subjects. |
| 6. A user can execute a program by providing his rights. |
| The communication between a subject and an object is established using protocols in the security architecture. Computers, data repositories, network and display devices are resources present in object. Grid computers make use of “user proxy” to access the resource needed for computation without user’s involvement. The life span of each proxy is in the hand of user. The drawbacks found in a user proxy are that it discovers complexity of credentials and restricts the user to limit the time duration. A “resource proxy” is employed for distributing access to resources. |
| To access a resource, a user proxy should request to resource proxy. A resource can be accessed only if the request is achieved. A request may fail, if there is no resource available. |
| An “exact” mapping should be available between a global and local subject. This is successful when we translate a global into local name with the help of a mapping table. But it produces some complexities. Hence this can be achieved using local authentication process. Then an accurate mapping is done finally. |
| Globus Security Infrastructure is a platform for implementing grid security architecture. It includes an infrastructure for wide range of computations. The Globus Security Infrastructure refers secure socket library for deriving authentication protocol. The implementation of this security architecture will be flexible to access resources based on access control security policy. |
METHOD AND SYSTEM FOR CONTROLLING USER ACCESS TO A RESOURCE IN A NERWORKED COMPUTING ENVIRONMENT |
| A networked computing environment uses a different approach to control files and other additional resources. This technique is executed in a multi user computer network. Computers exchange their resources through a communication pathway. In any network, a client system requests for a resource from the server system. A “peer server” is a computer that services both client and server. |
| Usually, a client can’t access all the resources that the server provides. Authentication of passwords is a mechanism that a client should possess a password to login. The access to resources is restricted by using other mechanisms such as access control lists, simple share/no-share switch, etc, Some Operating Systems includes complex and hard security models for new users. |
| A multi-user computer network consists of a client computer and a server computer in order to manage sharing of resources between users. The resources are arranged in a tree structure. The top of the tree has main element and the extra elements are arranged under the root node. Access permission is decided from the request. The first element of the tree contains the access control lists of the second element, because a copy of the access control lists is produced and it is inherited with the first element. When a request is found, it is sent to the first element in the tree. So, that the access control lists can be updated. The next request can be updated. The next request will be sent to the second element and the process continues. |
| Resources in a computer include files, folders or directories. This type of method modifies the access control mechanisms providing access to use resources. This method also employs both implicit access control and explicit access control techniques. |
| A security provider has direct access to a database. It includes specific hardware and software peripherals. It has to possess an authentication process in order to verify whether a user accessing a resource is a valid or an invalid user. |
| GUI are used among users and peer servers to communicate with one another. It also gives a way to modify the access permissions of a user. Modifying the access permissions doesn’t affect the local users. In a peer server, the resources allocated with the help of Operating System. The Operating System inherits the server components with the client components. It provides manipulation, propagation of resource protection and inheritance. Low – level protocol is used to access resource across the network. A request to modify the access permission is obtained form a user interface present in a peer server, while access the resource, if a user contains permission to use the resource, then the access is granted. The recent security models and its associated protocols can be employed in various networking systems. |
NIMROD/G: AN ARCHITECTURE FOR A RESOURCE MANAGEMENT AND SCHEDULING SYSTEM IN A GLOBAL COMPUTATIONAL GRID |
| The computational grids focus on providing access to high-end resources independent of their physical location and access pints. Some of the applications of computational grids enables a simple computational economy that includes a layer in which a user should select a “deadline”. Before the deadline the user should finish his task. This layer also collects the “price” amount for using the resource from that particular user. |
| In order to bring out the issues in parametric computing, a simple system known as “Mimrod” was formed. Mimrod implements bio-informatics and simulation of business processes. |
| Mimrod system becomes unsuccessful in dynamic computational grids. Hence a new system called called Nimrod/G was modeled with the help of globus middleware services. The architecture of Nimrod/G includes 5 components: |
| 1. Client/ user station - it serves as an user interface and monitoring console. A client can execute multiple instances of a single client from different locations. |
| 2. Parametric Engine- It serves as a persistent job control agent. It is responsible for managing and maintaining the whole process. It is used while jobs are created, to maintain job status, communicating with clients, schedule advisor and dispatcher. |
| 3. Scheduler- the scheduler duty is job assignment, resource creation and resource selection. |
| 4. Dispatcher - According to the schedulers instruction, the dispatcher will perform the execution of a task. |
| 5. Job wrapper- it acts as an intermediate between the parametric engine and the system where the task is performed. |
| Computational resources can be identified using scheduling system in two ways: |
| 1.A user instructs the Nimrod/G to finish the task before the deadline. |
| 2. A user can go into the system and tells an appropriate price for the resource as a request. |
| A benefit of this system is that whether an exact result is produced or not is known before itself. The scheduling policy is derived by including the set of parameters in scheduling system. These parameters are listed below: |
| 1. Architecture and configuration of resource |
| 2. Resource capability. |
| 3. Resource state, requirements and available nodes |
| 4. Access speed, priority and queue type |
| 5. Network bandwidth, load and latency |
| 6. Reliability of resource and connection |
| 7. User preference and capacity |
| 8. Application deadline and resource cost. |
| The scheduler collects all the information with the help of resource discoverer and obtains a single resource from that, which can satisfy all the resource requirement for better price. Nimrod/G components communicate with each other using TCP/IP sockets. Nimrod/G can be implemented using the Globs components such as GRAM(Globus Resource Allocation Manager), MDS(Metacomputing Directory Service), GSI(Global Security Infrastructure), GASS(Global Access to Secondary Storage), and GDIS(Grid Directory Information Services). The Nimrod/G mainly concentrates on resource management and scheduling in a computational grid. Nimred/G produces a best scheduling decisions using ser of parameters. |
CONCLUSION AND FUTURE WORK |
| Various methods developed for anonymizing data from 1998 to 2000 is discussed. Publishing microdata such as census or patient data for extensive research and other purposes is an important problem area being focused by government agencies and other social associations. The traditional approach identified through literature survey reveals that the approach of eliminating uniquely identifying fields such as social security number from microdata, still results in disclosure of sensitive data, k-anonymization optimization algorithm ,seems to be promising and powerful in certain cases ,still carrying the restrictions that optimized k-anonymity are NP-hard, thereby leading to severe computational challenges. k-anonimity faces the problem of homogeneity attack and background knowledge attack . The notion of ldiversity proposed in the literature to address this issue also poses a number of constraints , as it proved to be inefficient to prevent attribute disclosure (skewness attack and similarity attack), l-diversity is difficult to achieve and may not provide sufficient privacy protection against sensitive attribute across equivalence class can substantially improve the privacy as against information disclosure limitation techniques such as sampling cell suppression rounding and data swapping and pertubertation. Evolution of Data Anonymization Techniques and Data Disclosure Prevention Techniques are discussed in detail. The application of Data Anonymization Techniques for several spectrum of data such as trajectory data are depicted. This survey would promote a lot of research directions in the area of database anonymization. |
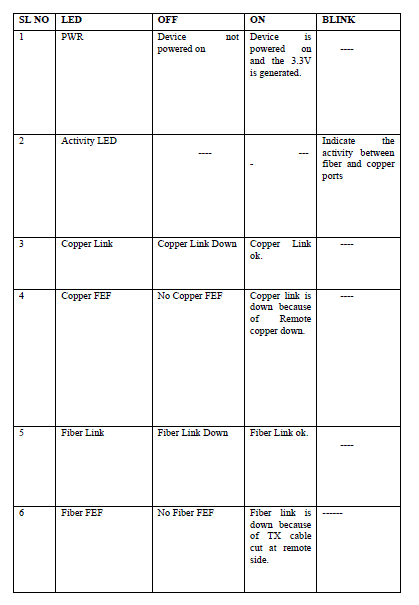
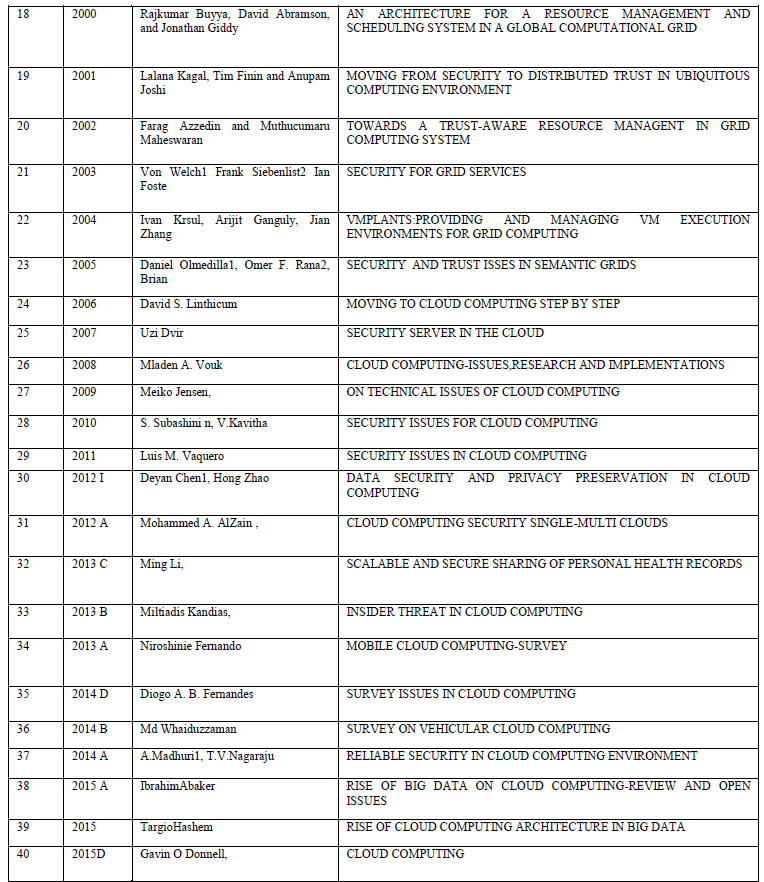
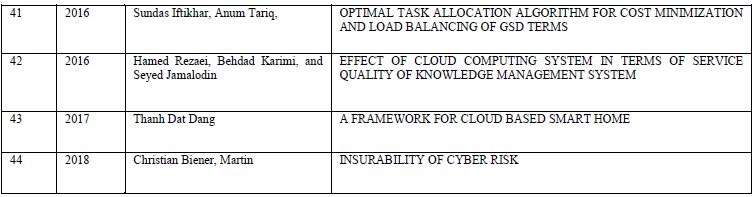
APPENDIX |
 |
 |
 |
References |
|