International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
| R.Rubini1, V.Gopi2 |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
Image scaling is the process of resizing a digital image. It is one of the most important methods used in various applications such as sharpening of an image, image zooming, preserving edge structures in an image and so on. This paper proposes an efficient scaling algorithm for designing an image scaling processor. The proposed scaling algorithm consists of two combined prefilters and one simplified bilinear interpolator. Besides, the replacement of spurious-power suppression technique (SPST) adder of a reconfigurable calculation unit is used to reduce power consumption and filter out the unused switching power. This paper also presents an efficient VLSI architecture for the existing method. The co-operation and hardware sharing techniques greatly decrease the hardware cost requirements. Compared to conventional schemes, the proposed image scaling processor design can reduce the memory requirement and needs only one-line buffer memory.
Keywords |
| Combined filter, image scaling, prefilter, Reconfigurable calculation unit (RCU), Very Large Scale Integration (VLSI), demosaicing, interpolation, controller ,Spurious-power suppression technique(SPST). |
INTRODUCTION |
| IMAGE scaling is the process of resizing a digital image. Scaling is a process, which is non-trivial that involves a trade-off between efficiency, smoothness and sharpness. Enlarging an image (upsampling or interpolating) is generally common for making smaller images fits in fullscreen mode. Scaling algorithms can be categorized into polynomial and non-polynomial-based algorithms. Nearest-neighbor algorithm is the uncomplicated simplest polynomial-based algorithm. One of the simplest ways of doubling its size is the nearest-neighbor interpolation, removing and then placing every pixel with four pixels possessing the same color. Nearest neighbor interpolation preserves these sharp edges, but it increases aliasing. Scaling algorithms such as bilinear and bicubic interpolation are the other polynomial-based algorithms. Filters used in the above mentioned algorithms are interpolating pixel color values, a continuous transition into the output even where the original material has discrete transitions are introduced. Linear (or bilinear, in two dimensions) interpolation is typically good for changing the size of an image[5], but causes some undesirable softening of details and can still remains blurred data and noisy artifacts. Better scaling technique such as bicubic interpolation [4]. In image processing, bicubic interpolation is often chosen over bilinear interpolation or nearest neighbor in image resampling, when speed should not be considered as a critical. Over the past decades, several non-polynomial based-algorithms [1-3] have been proposed. Bilateral filter [2], interpolation [1], and autoregressive model [3] are the techniques which have proposed earlier to enhance the image quality by reducing the blurring and aliasing artifacts. These image scaling polynomial-based methods are difficult to implement in VLSI. Thus, for real-time applications, less-complexity related algorithms are needed [5-9]. Concatenating of sharpening spatial and clamp filters efficiently develops the image quality with bilinear interpolation algorithm. |
 |
| By utilizing these algorithms, cost of the hardware and memory also reduced. In previous works, many high-quality interpolation-based methods [2]-[4] have been proposed. The existing methods effectively extend the image quality as well as decrease the artifacts of the blocking, aliasing, and blurring effects. Thus, for real-time applications, lesscomplexity image scaling processor algorithms are needed for VLSI implementation [3]-[5]. The rest of the paper is organized as follows. Section 2 narrates the related work of this paper. Section 3 formulates the framework of image scaling processor. Section 4 explains the algorithm for image scaling processor. Section 5 describes in detail about the implementation of VLSI architecture. Section 6 presents the simulation results and Section 7 concludes the paper. |
II.RELATED WORK |
| 1. Subpixel Edge Localization and the Interpolation of Still Images: |
| In this paper ,Subpixel edge localization and the interpolation of still images and apparatus provide edge enhancements as part of a demosaicing process in which an image is captured. By providing edge enhancements as part of the demosaicing process, the edge enhancement process has access to unaltered spatial and chromatic information contained in the raw captured image data. |
| 2. An Edge Guided Image Interpolation Algorithm via Directional Filtering and Data Fusion: |
| In this paper, An Edge guided Image Interpolation Algorithm via Directional Filtering And Data Fusion the preservation of edge structures is a challenge to image interpolation algorithms to reconstruct a high resolution from a low resolution counterpart. We propose a new edge-guided non-linear interpolation technique through directional filtering and data fusion. For a pixel to be interpolated two observation sets are defined in two orthogonal directions and each set produces an estimated value. These estimates of direction , modeled as different noisy measurements of the missing pixel are fused by the linear minimum mean square-error estimation (LMMSE) technique into a more robust estimate, using the statistics of the two observation sets. We also present a simplified version of the LMMSEbased interpolation algorithm to reduce computational cost without sacrificing much the interpolation performance. Experiments show that the new interpolation techniques can preserve sharp edges and reduce ringing artifacts |
III. FRAMEWORK OF IMAGE SCALING PROCESSOR |
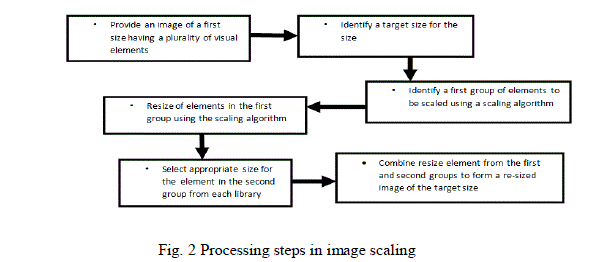
| Fig. 2, illustrates the processing steps in image scaling. The processing steps are as follows: |
| • Provide an image of a first size having a plurality of visual elements. |
| • Identify a target size for the size. |
| • Identify that the first group of elements should be scaled using a scaling algorithm. |
| • Resize of elements in the first group using the scaling algorithm. |
| • Combining the resized element from the first and second groups to form a re-sized image of the target size. |
 |
| Fig. 3. Depicts a common image processing device is a digital still camera. Thus, a typical image processing workflow for a current DSC is to capture an image using the Charge-couple device (CCD) array of light detectors, to transform the information from the light detectors into a raw captured image data (digital form) and to provide color to image data through a demosaicing process, to perform a white balancing process, to perform a chromatic improvement process. Finally, to perform an edge enhancement process |
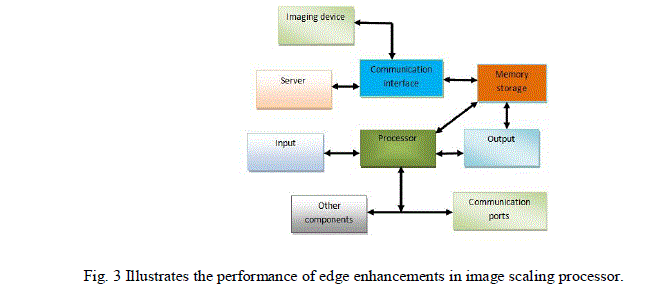 |
| Memory storage is a memory device to store data or information. It can be a random access memory (RAM), flash memory, etc. Processor is a processing device such as a high-speed microprocessor. It can access memory storage and process image data which is stored in memory. Output can be a display device such as, liquid crystal display (LCD) or other display devices. The image processing techniques described here can be implemented by both the hardware and software contained within image processing system. One method is to determine various functions which possess the similar shape in both the space domain and frequency domain. This strategy yields the result of various image interpolation algorithms. The higher resolution images yielded by this algorithm consisted of blocking artifacts. For the purpose of alleviating the blocking effects, the algorithm known as bilinear interpolation is introduced. Another method is called bicubic interpolation, which interpolates a signal by a weighted sum of values at control points to a spline function. The limitation of this algorithm is that the high frequency part of the original image is filtered due to the over smoothness of the cubic spline kernel which is depicted in fig. 4. |
 |
IV.ALGORITHM FOR IMAGE SCALING PROCESSOR |
| To decrease the blurring and aliasing artifacts caused by the bilinear interpolation, the sharpening spatial filter and clamp filter [6] are added as prefilters [5]. Initially, the input pixels of the images existing from the beginning are passed through a filter by the sharpening spatial filter to extend the edges and get rid of associated noise. Next, the filtered pixels are passed through a filter again by the clamp filter to smooth the noise and interpolate the missing samples along the edge direction. Coming to the end, the pixels are again filtered by the prefilters and then moved to the bilinear interpolation to perform up-1 downscaling. To protect the calculating resource and memory buffer, these prefilters are made understandable and joined to form a combined filter. |
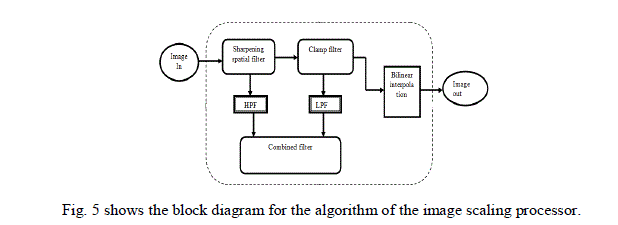 |
V. VLSI IMPLEMENTATION |
| The proposed image scaling processor comprises of two concatenated prefilters and an understandable bilinear interpolator. The bilinear interpolator will gain two input pixels from the above mentioned prefilters without the necessity of additional line-buffer memory, is utilized for VLSI implementation. Fig. 6. illustrates the block diagram of the Very Large Scale Integration architecture for the proposed image scaling processor design. It comprises of 4 important modules, named as register bank, a sharpening spatial filter and a clamp filter joined to form a combined filter, a controller and a bilinear interpolation. The following subsections describes the function of each modules. |
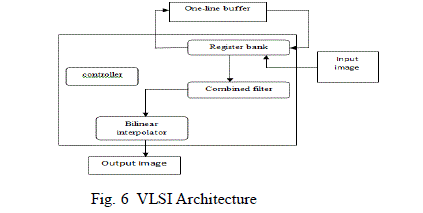 |
| A. Architecture of the Register Bank |
| In this using a few words, T-model or inversed T-model is passing through a filter to yield the result pixels of by the utilization of ten source pixels. The design of a register bank is utilized to provide the 10 values for the sudden consumption of the T-model, and requires a one-line buffer memory. |
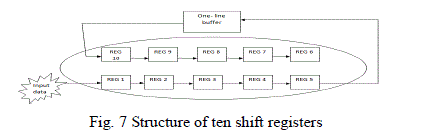 |
| B. Architecture of the proposed combined filter |
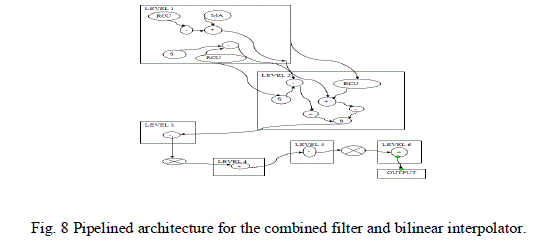 |
| Fig.8. illustrates the architecture model of combined filter and bilinear interpolator for the 6-stage based on pipelined feature, to reduce the delay paths to enhance the function by implementing the pipeline. Fig.8. depicts the scheduling of a combined filter in first and second stages. This results in the reduction of memory from 4 to 1 line buffer as implemented earlier [3]. The architecture of the RCU is depicted in Fig. 10. 3 (MUX), 4 shifters, 1 sign circuit and 3 adders are implemented in RCU. Due to this RCU design, the hardware expensive cost is decreased in the combined filter |
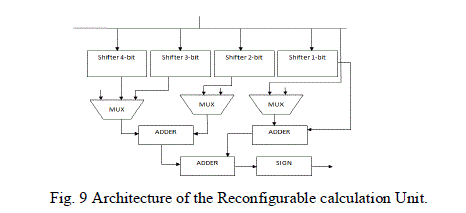 |
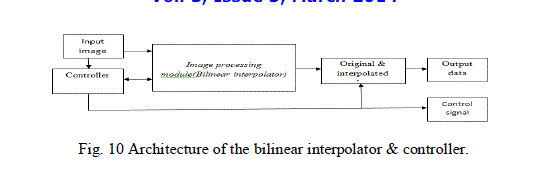
| C. Architecture of bilinear interpolator and controller |
| In Fig. 8. the levels depicts the 3,4,5 and 6 architecture for 4-stage pipeline and multipliers for 2-stage pipeline are utilized for the reduction of path delay for the bilinear interpolator. The implementation of controller is achieved by the FSM (finite-state-machine) circuit. Fig.10 depicts the signals for controlling the time and various stages of pipeline in the VLSI architecture of the register bank, combined filter, bilinear interpolator. |
 |
VI. SIMULATION RESULTS |
| A low-cost and high-quality image scalar was proposed for previous work. It successfully improves the image quality by adding sharpening spatial and clamp filters as prefilters with an adaptive technique based on the algorithm of bilinear interpolation. Although the expensive cost of hardware and requirement of memory had been reduced. In existing work the demand of memory still costs four line buffers. In the proposed system use only one line buffer instead of four line buffer so the area of proposed system will be decrease compared to previous work. A reconfigurable calculation unit designed by using number of shifters, multiplexers and three binary adder circuits. |
| (1) Normal binary adder have consumed more power, |
| (2) Also pixels are represent in gray level for 8 bit binary representation so the repeated addition are performed in binary adders so the switching power are increased. |
| To overcome the above mentioned problem to replace spurious-power suppression technique (SPST) adder of a reconfigurable calculation unit to reduce power consumption and filter out the unused switching power. |
| The Very Large Scale Integration architecture for the image scaling processor is coded by the hardware description language called VHDL. The design of a register bank is utilized to provide 10 values for the consumption of the Tmodel, and requires a single line buffer memory is coded and simulated by the synthesis of Xilinx ISE Simulator is depicted in fig.11. |
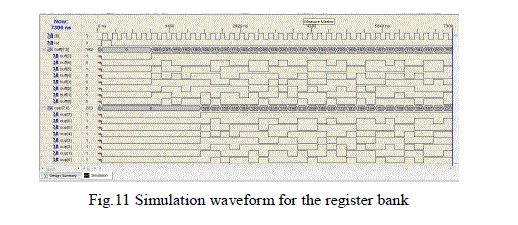 |
| VLSI architecture for the combined filter can be implemented by the filtration of the full image by the utilization of one-line buffer memory. This results in the reduction of memory from multiple to single line buffer memory. The proposed model of combined filter and bilinear interpolator for the reduction of delay paths to enhance the function of pipeline is also simulated in Xilinx ISE Simulator is depicted in fig.12. |
 |
VII.CONCLUSION |
| The image scaling algorithm consists of a combined filter and a bilinear interpolation. To reduce the smoothness and denoising artifacts produced by the bilinear interpolator, the sharpening spatial and clamp filters are formed as combined filters. To minimize the memory buffers and computing resources for the proposed image processor design, a T-model and inversed T-model high and low-pass filters are created for realizing the combined filter. Furthermore, two T-model or inversed T-model filters are combined into a combined filter which requires only a one-line-buffer memory. Moreover, SPST adder unit is replaced for decreasing the power consumption of a reconfigurable calculation unit. In addition, the computing resource and hardware cost of the bilinear interpolator can be efficiently reduced by an algebraic manipulation and hardware sharing techniques. Compared with previous low-complexity techniques, this work and requires only a one-line-buffer memory. |
References |
|