An Extensive growth in software technologies results in tampering of images. A major problem that occurs in the real world is to determine whether an image is authentic or forged. Copy-Move Forgery Detection is a special type of forgery detection approach and widely used under digital image forensics. In copy-move forgery, a specific area is copied and then pasted into any other region of the image. The main objective of this paper is to detect the multiple copies of the same region and different regions. In this paper, keypoint-based method are used. In keypoint-based method, SURF (Speeded Up Robust Features) method is used for feature extraction. The g2NN strategy is done for identifying the matched points. Then the Agglomerative Hierarchical Clustering is done on the matched points so that false detection rate can be reduced
Keywords |
| Copy-Move Forgery, SURF, HAC, image
forensics, g2NN strategy. |
INTRODUCTION |
| The goal of blind image forensics is to determine
the authenticity and origin of digital images without the
support of an embedded security scheme [1]. Within this
field, copy-move forgery detection (CMFD) is probably
the most actively investigated subtopic [2]. A copymove
forgery denotes an image where part of its content
has been copied and pasted within the same image.
Typical motivations are either to hide an element in the
image [3], or to emphasize particular objects. Copymove
Forgery Detection methods are either keypointbased
methods or block-based methods. Keypoint-based
methods compute their features only on image regions
with high entropy, without any image subdivision for feature extraction. Similar features within an image are
afterwards matched. There are two types of keypointbased
methods such as Scale Invariant Feature Transform
(SIFT) [8], [18] and Speeded Up Robust Features (SURF)
[11]. Block-based methods subdivide the image into
rectangular regions that is tile the image into overlapping
blocks for feature extraction. For every such region, a
feature vector is computed. Similar feature vectors are
subsequently matched. There are 13 block-based features
and it can be grouped into four categories: Moment-based
(Blur, Hu, Zernike [12]), Dimensionality reduction-based
(PCA [5], SVD, KPCA [6]), Intensity-based (Luo, Bravo,
Lin [7], Circle), Frequency-based (DCT [9], DWT [6],
FMT [4]). The main goal of this paper is to detect the
multiple copies of the same region and detect the multiple
copies of different region. |
 |
| The paper is organized as follows. The Section II
describes the proposed work. Section III discuss about the
employed error metrics. Section IV focus on results and
observations. Section V discuss about performance analysis. Section VI contains a conclusion and future
work. |
II. PROPOSED METHOD |
| Copy-Move Forgery Detection has five steps. The
block diagram for copy-move forgery detection is shown
in Figure 2. |
| A. Pre-Processing |
| Here the image is converted from RGB to Gray
representation. |
| B. Feature Extraction |
| The features can be extracted by using SURF
(Speeded Up Robust Features) method. SURF is the
robust local feature detector. It is based in sums of 2D
Haar Wavelet responses and makes an efficient use of
integral images. SURF features can be extracted using the
following steps: |
| Integral Image
Keypoint Detection
Orientation Assignment
Feature Descriptor Generation |
| 1) Integral Image: |
| Integral Image increases the computation
speed as well as the performance, its value is calculated
from an upright rectangular area, the sum of all pixel
intensities is calculated by the formula, |
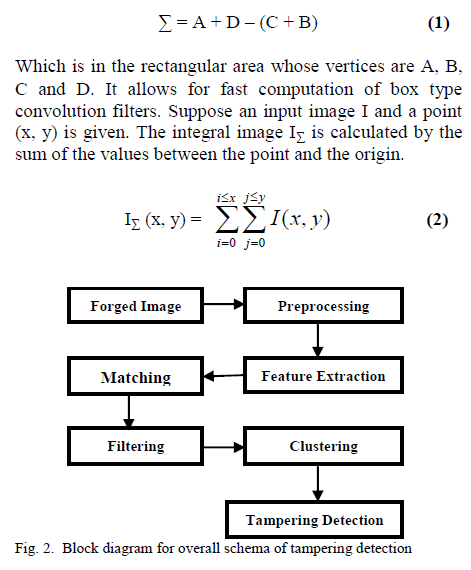 |
| 2) Keypoint Detection: |
| This step requires scale space generation for
the extraction of keypoints. To detect the blob-like
structures at locations where the determinant is maximum. |
| In SURF Laplacian of Gaussian is approximated with a
box filter. Convolution is applied to an image with
varying size box filter for creating the scale space. After
constructing the scale space, determinant of the Hessian
matrix is calculated for detecting the extremum point. If
determinant of the Hessian matrix is positive that means,
both the Eigen values are of the same sign either both are
negative or both are positive. |
| In case of the positive response, points will
be taken as extrema otherwise it will be discarded.
Hessian matrix is represented by, |
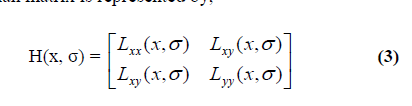 |
| Where, Lxx (x, σ) is the convolution of the Gaussian
second order derivative with the image I in point x, and
similarly Lxy(x, σ) and Lyy(x, σ). These derivatives are
called as Laplacian of Gaussian. The 9 × 9 box filters are
approximation of the Gaussian and represent lowest scale
for computing the blob response maps. The approximate
determinant of the Hessian matrix is calculated by: |
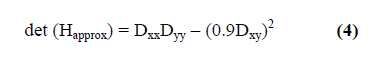 |
| Where 0.9 represents the weights applied to the
rectangular regions are simple for computational
efficiency. The relative weight of the filter responses is
used to balance the expression for the Hessian’s
determinant. The approximated determinant of the
Hessian represents the blob response in the image at the
specified location. These responses are stored in a blob
response map over different scales, and local maxima are
detected. |
| 3) Orientation Assignment: |
| At first a circular area is constructed around
the keypoints. Then Haar wavelets are used for the
orientation assignment. It also increases the robustness
and decreases the computational cost. Haar wavelet
responses are calculated within a circular neighborhood
of some radius around the interest point. Haar wavelets
are filters that detect the gradients in x and y directions.
In order to make rotation invariant, a reproducible
orientation for the interest point is identified. Once the
wavelet responses are calculated and weighted with the
Gaussian centered at the interest points, the responses are
represented as points in a space with the horizontal
response strength and the vertical response strength.
The dominant orientation is estimated by
calculating the sum of all responses within a sliding
orientation window. The horizontal and vertical responses
within the window are summed. The two summed
responses then yield a local orientation vector. The
longest such vector over all windows defines the
orientation of the interest point. A circle segment of 600
is rotated around the interest point. The maximum value
is chosen as a dominant orientation for that particular
point. |
| 4) Feature Descriptor Generation: |
| For generating the descriptors, first construct
a square region around an interest point, where interest
point is taken as the center point. This square area is again
divided into 4 × 4 smaller subareas. For each of this cell
Haar wavelet responses are calculated. Here dx, termed as
horizontal response and dy, as vertical response.
Horizontal and vertical response represents the selected
interest point orientation. The wavelet responses dx and dy
are summed up over each sub-region and form a first set
of entries in the feature vector. And then extract the sum
of the absolute values of the responses | dx | and | dy |. For
each of this sub region 4 responses are collected as: |
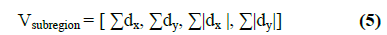 |
| So each sub region contributes 4 values. Therefore the
descriptor is calculated as 4 × 4 × 4 = 64. |
| C. Matching |
| A matching operation is performed among the
feature vectors to identify similar local patches in the
image. In the existing work, Approximate Nearest
Neighbor method is used for feature matching. It uses
multiple randomized kd-trees for a fast neighbor search. It
detects only the single copy-move region. In this paper,
matching is done by using g2NN strategy. The
generalized 2NN test starts from the observation that in a
high dimensional feature space, features that are different
from one considered share very high and very similar
values among them [7]. It consists of iterating the 2NN
test between di/di+1 until this ratio is greater than the
threshold value T1. |
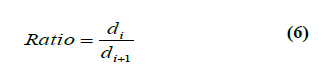 |
| If k is a value in which the procedure stops, each
keypoint in correspondence to a distance in {d1,…,dk}
(where 1 ≤ k < n) is considered as a match for the
inspected feature. It is able to detect the multiple copies of
the same region. For further processing, the matched
keypoints are used. The unmatched keypoints can be left
out. |
| D. Filtering |
| Filtering schemes are used to reduce the probability
of false matches. Neighboring pixels often have similar
intensities, which can lead to false forgery detection. The
Euclidean distance that can be calculated between each
feature vectors. The pairs can be removed if it is less than
the particular threshold value T2. |
| E. Clustering |
| The Agglomerative Hierarchical Clustering is used
to cluster the forged regions. It is done on the matched
keypoints. This is done in order to avoid the false
positives. Hierarchical clustering involves tree like
structure.
The hierarchical clustering involves the following
steps.
1. Assign each keypoint to a cluster. |
| 2. Compute all the reciprocal spatial distances
among the clusters.
3. Finds the closest pair of clusters.
4. Merges them into single cluster. |
| The clustering is done iteratively until certain
threshold is reached. The inconsistency coefficient is
compared with threshold, to stop cluster grouping. The
linkage method is used to find the distance between the
set of observations. Ward’s Linkage method is used. |
| 1) Ward’s Linkage: |
| The Error Sum of Squares (ESS) is calculated
and the increment or decrement is evaluated when the
cluster is joined to a single one |
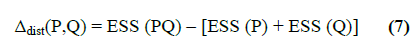 |
| If the cluster detected his significant number of
matched keypoints, then the cluster is eliminated. The
clusters that have more than two matched keypoints are
considered to be matched cluster. If more than two such
clusters found, the image is considered to be forged
image. |
III. ERROR MEASURES |
| It analyzes the performance of evaluating copy-move
forgery detection algorithms at image level. It focuses on
whether the fact that an image has been tampered or not
to be detected. The measures precision and recall can be
calculated by |
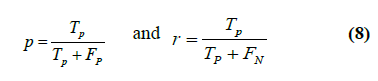 |
| Where TP - The number of correctly detected forged
images.
FP
- The number of images that have been
erroneously detected as forged.
FN
- Falsely missed forgery images.
Precision denotes the probability that a detected
forgery is truly a forgery; while Recall shows the
probability that a forged image is detected. Recall is
often also called true positive rate. score as a measure
which combines precision and recall in a single value. |
 |
| Where p represents precision and r represents recall. |
IV. RESULTS AND DISCUSSION |
| Results for detecting single and multiple copy-move
forgery are shown below. Figure 3, 4 and 5 shows the
results for detecting copy move image forgery. Some part
of the original image has been copied to other areas to get
a forged image. |
| A. Detection of Multiple copies of same region. |
| Figure 3 shows the result for detecting multiple
copies of the same region. The original image and the
forged image are shown in figure (a) and (b) respectively. |
| Some part of the original image has been copied and
pasted it into multiple times of the same region. Figure (c)
is the pre-processed forged image. Figure (d) shows the
feature extraction for forged image. Figure (e) shows the
location in which the forgery has been identified. |
 |
| B. Detection of Single Copy-Move Forgery
Figure 4 shows the results for detecting single
copy move forgery. The original image and the forged
image are shown in figure (a) and (b) respectively. Some
part of the original image has been modified to get a
forged image. Figure (c) is the pre-processed forged
image. Figure (d) shows the feature extraction for forged
image. Figure (e) shows the location in which the forgery
has been identified. |
 |
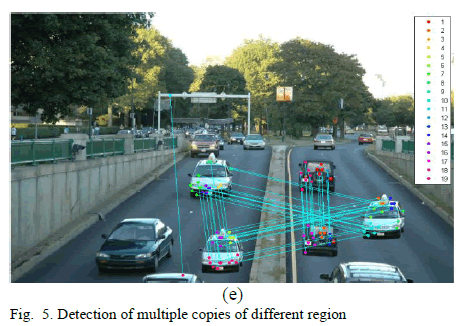
| C. Detection of multiple copies of different regions
Figure 5 shows the results for detecting multiple
copies of different regions. The original image and the
forged image are shown in figure (a) and (b) respectively.
Two different parts of the original image has been
modified to get a forged image. Figure (c) is the preprocessed
forged image. Figure (d) shows the feature
extraction for forged image. Figure (e) shows the location
in which the forgery has been identified |
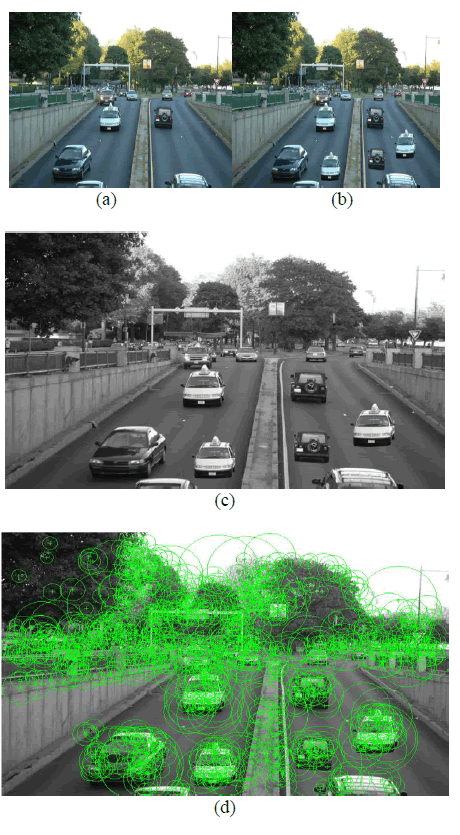 |
 |
V. PERFORMANCE ANALYSIS |
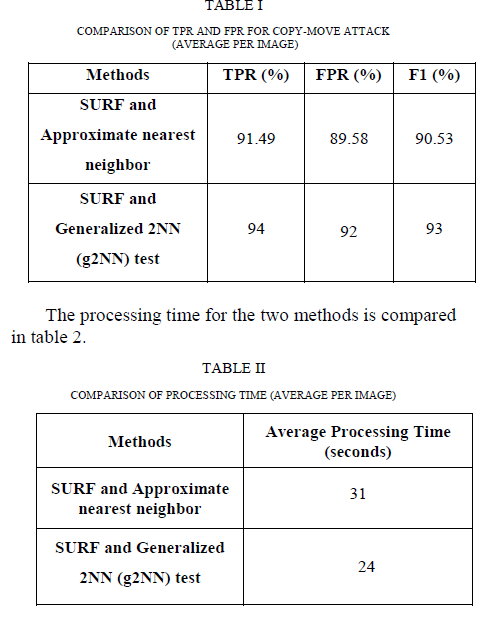
| Table 1 shows the performance analysis for SURF
method to detect copy-move forgery based on the error
measures. The True Positive Rate and False Positive Rate
are determined for the tested images and the performance
for the existing method is compared with this work. |
 |
VI. CONCLUSION |
| This work is used to find whether the image is forged
one or not. This work deals with the detection of copymove
attack. The paper detects the multiple copies of
same region and multiple copies of different region of
copy-move forgery. The features can be extracted by
using keypoint method called SURF. The g2NN matching
is done to match the features. The filtering is done to
avoid similar match features. In order to avoid false positives, agglomerative hierarchical clustering is done
and finally to identify the image is forged or not.
This work does not identify other types of image
tampering techniques such as enhancing and splicing
attack and it identifies only the copy move forgery. The
future work is to identify such attacks. |
References |
- V Christlein, C Riess, J Jordan, C Riess, and E Angelopoulou, âÃâ¬ÃÅAnEvaluation of Popular Copy-Move Forgery Detection Approaches,âÃâ¬ÃÂIEEE Trans. Inf. Forensics Security, vol. 7, no. 6,p. 1841âÃâ¬Ãâ1854,Dec. 2012.
- J. Redi, W. Taktak, and J.-L. Dugelay, âÃâ¬ÃÅDigital image forensics: Abooklet for Beginners,âÃâ¬Ã Multimedia Tools Applications, vol. 51, no.1, pp. 133âÃâ¬Ãâ162, Jan. 2011.
- H. Farid, âÃâ¬ÃÅA survey of image forgery detection,âÃâ¬Ã Signal Process.Mag., vol. 26, no. 2, pp. 16âÃâ¬Ãâ25, Mar. 2009.
- S. Bayram, H. Sencar, and N.Memon, âÃâ¬ÃÅAn efficient and robustmethod for detecting copy-move forgery,âÃâ¬Ã in Proc. IEEE Int. Conf.Acoustics, Speech, and Signal Processing, Apr. 2009, pp. 1053âÃâ¬Ãâ1056.
- A. Popescu and H. Farid, âÃâ¬ÃÅExposing Digital Forgeries by DetectingDuplicated Image RegionsâÃâ¬ÃÂ, Department of Computer Science,Dartmouth College, Tech. Rep. TR2004-515, 2004
- M. Bashar, K. Noda, N. Ohnishi, and K. Mori, âÃâ¬ÃÅExploringduplicated regions in natural images,âÃâ¬Ã International Journal ofComputer Applications (0975 âÃâ¬Ãâ 8887).
- H. Lin, C. Wang, and Y. Kao, âÃâ¬ÃÅFast copy-move forgery detection,âÃâ¬ÃÂWSEAS Trans. Signal Process., vol. 5, no. 5, pp. 188âÃâ¬Ãâ197, 2009.
- I. Amerini, L. Ballan, R. Caldelli, A. D. Bimbo, and G. Serra, âÃâ¬ÃÅASIFT-based forensic method for copy-move attack detection andtransformation recovery,âÃâ¬Ã IEEE Trans. Inf. Forensics Security, vol.6, no. 3,p. 1099âÃâ¬Ãâ1110, Sep. 2011.
- J. Fridrich, D. Soukal, and J. Lukas, âÃâ¬ÃÅDetection of copy-moveforgery in digital images,âÃâ¬Ã Proc. Digital Forensic ResearchWorkshop, Cleveland, OH, August 2003.
- [10] J. S. Beis and D. G. Lowe, âÃâ¬ÃÅShape indexing using approximatenearest neighbor search in high-dimensional spaces,âÃâ¬Ã in Proc.IEEE Conf. Computer Vision and Pattern Recognition, Jun. 1997,pp. 1000âÃâ¬Ãâ1006.
- B. L. Shivakumar and S. Baboo, âÃâ¬ÃÅDetection of region duplicationforgery in digital images using SURF,âÃâ¬Ã Int. J. Comput. Sci. Issues,vol. 8, no. 4, pp. 199âÃâ¬Ãâ205, 2011.
- S. Ryu, M. Lee, and H. Lee, âÃâ¬ÃÅDetection of copy-rotate-moveforgery using Zernike moments,âÃâ¬Ã in Proc. Information HidingConf., Jun. 2010, pp. 51âÃâ¬Ãâ65.
- X. Pan and S. Lyu, âÃâ¬ÃÅRegion duplication detection using imagefeature matching,âÃâ¬Ã IEEE Trans. Inf. Forensics Security, vol. 5, no.4, pp.857âÃâ¬Ãâ867, Dec. 2010.
- V. Christlein, C. Riess, J. Jordan, C. Riess, and E. Angelopoulou ,âÃâ¬ÃÅSupplemental Material to an Evaluation of Popular Copy-MoveForgery Detection ApproachesâÃâ¬Ã Aug. 2012.
- V. Christlein, C. Riess, and E. Angelopoulou, âÃâ¬ÃÅA study on featuresfor the detection of copy-move forgeries,âÃâ¬Ã in Proc. GISICHERHEIT, Berlin, Germany, Oct. 2010, pp. 105âÃâ¬Ãâ116.
- M. Muja and D. G. Lowe, âÃâ¬ÃÅFast approximate nearest neighborswith automatic algorithm configuration,âÃâ¬Ã in Proc. Int. Conf.Computer Vision Theory and applications, Feb. 2009, pp. 331âÃâ¬Ãâ340.
- J. Zhang, Z. Feng, and Y. Su, âÃâ¬ÃÅA new approach for detecting copymove forgery in digital images,âÃâ¬Ã in Proc. Int. Conf. CommunicationSystems, Nov. 2008, pp. 362âÃâ¬Ãâ366.
- H. Huang, W. Guo, and Y. Zhang, âÃâ¬ÃÅDetection of copy-move forgeryin digital images using SIFT algorithm,âÃâ¬Ã in Proc. Pacific-AsiaWorkshop on Computational Intelligence and IndustrialApplication, Dec. 2008, vol. 2, pp. 272âÃâ¬Ãâ276.
|