International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| S.S.Karthick kumar and G.Indhumathy Dept of Computer science and Engineering, Velammal College of Engineering and Technology, Madurai, Tamilnadu, India. |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In Efficient driving direction system, the GPS-equipped vehicle are used as mobile sensors thereby probing the traffic rhythm of a city. It helps the drivers in choosing driving directions. The smart driving directions can mine from the historical GPS trajectories. A timedependent landmark graph is framed with the view of modeling the dynamic traffic pattern and also the intelligence of experienced drivers. Hence it helps assist the user by providing the practically fastest route to a given destination at a given time of departure. The Variance Entropy-Based Clustering method is employed to estimate the distribution of travel time between two landmarks in different time slots. Taking this graph as a basis, a two-stage routing algorithm is used to compute the practically fastest and customized route for end users. Necessarily, the time taken by a driver to traverse a route depends on the following aspects: 1) The physical feature of a route such as distance, capacity (lanes), and the number of traffic lights, number of direction turns; 2) The time-dependent traffic flow along the route; 3) The driving behavior of a user.
Keywords |
| Driving Directions, Time-Dependent Fast Route, Taxi Trajectories, Landmark Graph |
INTRODUCTION |
| GPS-equipped taxis can be considered as mobile sensors to analysis the traffic on road surfaces, and experienced taxi drivers can easily determine the fastest (quickest) route to a given destination based on their knowledge. Smart driving directions will be mine from the historical GPS trajectories of a large number of taxis, and will provide the user with the practically fastest route to a given destination at a given time of departure. The time-dependent landmark graph, has been proposed where a node (landmark) is a frequently traversed road segment with the view of modeling the intelligence of the taxi drivers and the properties of dynamic road networks. Then, a Variance-Entropy-Based Clustering strategy is applied to estimate the distribution of the travel time between two landmark edges for different time slots. Based on this graph, a two-stage routing algorithm has been designed to compute the practically fastest route. . The application such as route planner [7], hot route finder [16], traffic flow analysis [15] have uses the information from Gps data to achieve the better quality of service. |
| Discovering efficient driving directions has become an essential activity and has been implemented as a key feature in many map service providers like Google and Bing Maps. A fast driving route saves not only the driver’s but also the energy consumption (as most gas is wasted in traffic jam). In practice, big cities with serious traffic problems usually have a large number of taxis traversing on road surfaces. For the sake of management and security, these taxis have already been embedded with a GPS sensor, which enables a taxi to report on its present location to a data center in a certain frequency. Thus, a large number of time-stamped GPS trajectories of taxis have been accumulated and are easy to obtain. Intuitively, taxi drivers are experienced drivers who can usually find out the fastest route to send passengers to a destination based on their knowledge Apart from the distance of a route, they also consider other factors, such as the time-variant traffic on road surfaces, traffic signals and direction changes contained in a route, as well as the probability of accidents for the selection of driving direction. These factors can be learned by experienced drivers but are too subtle and difficult to incorporate into existing routing engines. Therefore, these historical taxi trajectories, which imply the intelligence of experienced drivers, provide us with a valuable resource to learn practically fast driving directions. |
PROBLEM DEFINITION |
| Intelligence Modeling: As a user is free to select any place as source or destination, there would be no trajectory exactly passing the query points. It is difficult to answer the queries of the user by directly mining the trajectory patterns from the data. Therefore, how to model the intelligence of the taxi drivers that can answer a variety of queries is a challenge |
| Data Sparseness and Coverage: we cannot guarantee there are sufficient GPS equipped vehicle traversing on each road segment even though there are a large number of vehicles. That is we cannot accurately estimate the speed pattern of each road segment. |
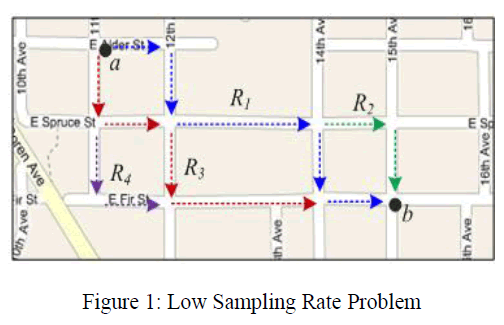 |
| Low-sampling-rate Problem: GPS equipped vehicle location will be recorded in a very low frequency say 2-5 minutes per point so as to save energy and communication loads [2]. This increases the uncertainty of the roots transverse by taxi [3]. The data obtain from gps trajectories is not precious due to sampling error [17]. |
IMITATIONS OF OTHER TECHNIQUES |
| Most of the existing mathematics approaches employee the local or incremental algorithms that map current or neighboring positions on to the vector road segments on a map. The current position result will be greatly affected by the measurement errors. |
 |
ARCHITECTURE |
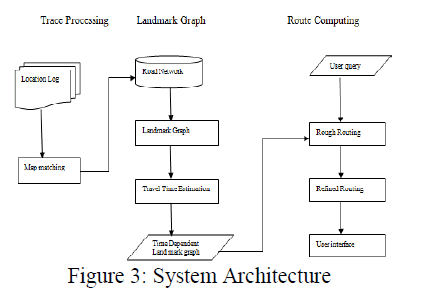
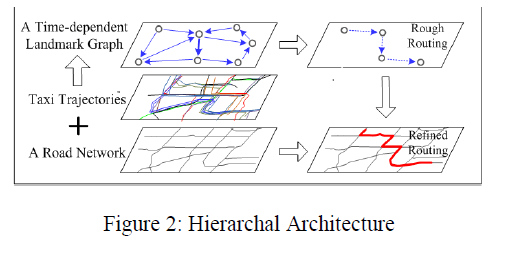
| The architecture of our system consists of three major components: Trajectory Preprocessing, Landmark Graph Construction, and Route Computing. The first two components operate offline and the third is running online. The online parts only need to be performed once unless the trajectory archive is updated. Trajectory Preprocessing: This component first segments GPS trajectories into effective trips, then matches each trip against the road network. |
| 1) Trajectory segmentation: A tag is associated with a GPS enable vehicles reporting the locations of vehicle |
| 2) Map matching: While dealing with the lowsampling- rate trajectories, and to map each GPS point of a trip to the corresponding road segment the IVMM algorithm, has a better map-matching algorithm than existing map matching algorithm. Landmark Graph Construction: The separate trajectories for the week-days and weekend has been constructed to build the landmark graphs for weekdays and weekends respectively .The two landmarks has been connected with a landmark edge if there are a certain number of trajectories passing these two landmarks. , the distribution of travel time for each landmark edge has been calculated using the VEclustering algorithm. |
| Route Computing: For a given a query (qs, qd, td), two-stage routing algorithm will be carried to find out the fastest route. In the first stage, rough routing will searches the time-dependent landmark graph for the fastest rough route represented by a sequence of landmarks. In the second stage, the refined routing algorithm will be employed to compute a detailed route in the real road network to sequentially connect the landmarks in the rough route. |
 |
| The trajectories has been build for that different weekdays (e.g. Tuesday and Thursday) almost share similar kinds of traffic patterns while the weekdays and weekends have different patterns. Therefore two different landmark graphs are built for weekdays and weekends respectively. All the weekday trajectories (from different weeks and months) into one weekday landmark graph, and put all the weekend trajectories into the weekend landmark graph. The threshold δ is used to eliminate the edges that are seldom traversed by taxis, because, fewer the taxis that pass two land-marks, lower the accuracy of the estimated travel time (between the two landmarks). Additionally, the tmax value used to remove the landmark edges has a very long travel time. Due to the low-sampling-rate problem, sometimes, a taxi may consecutively traverse three landmarks while no point is recorded while passing the middle (second) one. This will result the travel time between the first and third landmark being very long. Such types of edges will increase the space complexity of a landmark graph and results inaccuracy to the travel time estimation. |
| A. Trajectory Preprocessing: |
| This component first segments GPS trajectories into effective trips, then matches each trip against the road network. 1) Trajectory segmentation: In practice, a GPS log may record a taxi's movement of several days, in which the taxi could send multiple passengers to a variety of destinations. Therefore, we partition a GPS log into some taxi trajectories representing individual trips according to the taximeter's transaction records. |
| B. Landmark |
| A landmark is one of the top-k road segments that are frequently traversed by taxi drivers according to the trajectory archive. The reason for using the “landmark” for modeling the taxi drivers' intelligence is: 1) the notion of landmarks follows the natural thinking pattern of people, and can give the user with more understandable and memorable presentation of driving directions beyond detailed descriptions. For instance, the typical pattern that people introduce a route to a driver is like this take I-406 |
| East at NE 5th Street, then change to I-90 at exit 11, and finally exit at Qwest Field". Instead of giving turnby- turn directions, people prefer to use a few landmarks (like NE 5th Street) that highlight key directions to the destination. |
| 2) The low sampling-rate and sparseness of the taxi trajectories do not support the speed estimation for each road segment while the traveling time between two landmarks can be estimated. Meanwhile, the lowsampling- rate trajectories cannot offer sufficient information for inferring the exact route here, top-k road segments can be detect as the landmarks instead of setting up a fixed threshold. |
| familiarity of routes. For example, people who are familiar with a route can usually pass the route faster than a new-comer. Sometimes, even on the same path, cautious people are likely to drive relatively slower than those preferring to drive quickly and aggressively. |
| E. Clustering |
| The number of clusters and the boundary of these clusters vary in different landmark edges, therefore the following V-Clustering instead of using some k-meanslike algorithm or a predefined partition. V-Clustering: VE clustering [1] is an two phase clustering method to learn different time partitions for different land mark edges based on trajectories. We first sort Tuv according to the values of travel time (tl- ta), and then partition the sorted list L into several sub-lists in a binary-recursive way. In each iteration, compute the variance of all the travel times in L. Later, find out the best split point having the minimal weighted average variance (WAV) defined |
| WAV(i;L) =|L1(i)|/|L|Var(L1(i)) +=|L2(i)|/|L| |
 |
| 10 eturn D = {D1;D2…………….,Dk}; |
CONCLUSION AND FUTURE WORKS |
| This approach finds out the practically fastest route to a destination at a given departure time in terms of taxi drivers' intelligence learned from a large number of historical taxi trajectories. First step to construct a timedependent landmark graph, and then perform a two-stage routing algorithm based on this graph to find the fastest route. Significantly outperforms both the speedconstraint- based and the real-time traffic-based method in the aspects of effectiveness and efficiency. However there exist some problems that a recommended route would become crowded if many people take it. |
| This is the common problem of Path-finding, and this problem is even worse (than ours) in present shortest-path and real-time-traffic-based methods (as our method can be customized for different drivers). In the future, this can be solved by using some strategies, such as load balance and data update |
References |
|