International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| K.Padmapriya, A.Ambika and A.Gayathiri M.E, Department Of CSE(Final Year), Bharath Niketan Engineering College, Aundipatti, Tamil Nadu, India. |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Entity Recognition is process of identifying predefined entities such as person names, products, or locations in a given document. This is done by finding all possible substrings from a document that match any reference in the given entity dictionary. Approximate Membership Extraction (AME) method was used for finding all substrings in a given document that can approximately match any clean references but it generates many redundant matched substrings because of approximation (rough calculation), thus rendering AME is not suitable for real-world tasks based on entity extraction. We propose a web-based join framework which combines a web search along with the approximate membership localization. Our process first provides a top n number of documents fetched from the web using a general search using the given query and then approximate membership localization(AML) is applied on these documents using the clear reference table and extracts the entities form the document to form the intermediate reference table using Edit distance Vector, Score Correlation.
Keywords |
| Data Mining, Approximate Membership Localization Algorithm, P-Prune, Entity Recognition. |
INTRODUCTION |
| The task of Entity Recognition is to identify predefined entities such as person names, products, or locations in this document. With a potentially large dictionary, this entity recognition problem transforms into a Dictionary-based Membership Checking problem, which aims at finding all possible substrings from a document that match any reference in the given dictionary. With the growing amount of documents and the deterioration of documents’ quality on the web, the membership checking problem is not trivial given the large size of the dictionary and the noisy nature of documents, where the mention of the references can be approximate and there may be mentions of non-relevant references. |
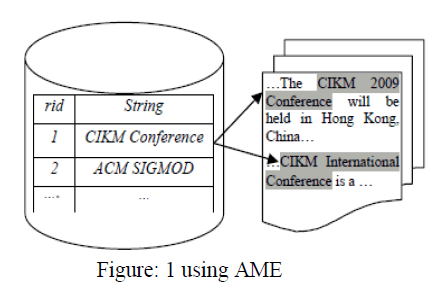 |
| The approximation is usually constrained by a similarity function (such as edit distance, jaccard, cosine similarity, etc.) and a threshold within [0, 1], such that slight mismatches are allowed between the substring and its corresponding dictionary reference. For instance, given a list of conference names like “CIKM Conference,” “ACM SIGMOD Conference,” Conference” as shown on the left part of Fig. 1, the task is to find matches from the text on the right, such as “CIKM 2009 Conference” and “CIKM International Conference,” although they do not match the string “CIKM Conference” in the dictionary exactly. The dictionary-based approximate membership checking process is now expressed by the Approximate Membership Extraction (AME), finding all substrings in a given document that can approximately match any clean references. |
| In this project, we propose a new type of membership checking problem: Approximate Membership Localization (AML). AML only aims at locating true mentions of clean references. AML targets at locating non-overlapped substrings in a given document that can approximately match any clean reference. We also increase the performance of the AML process making it as a Web-Based Join Framework. |
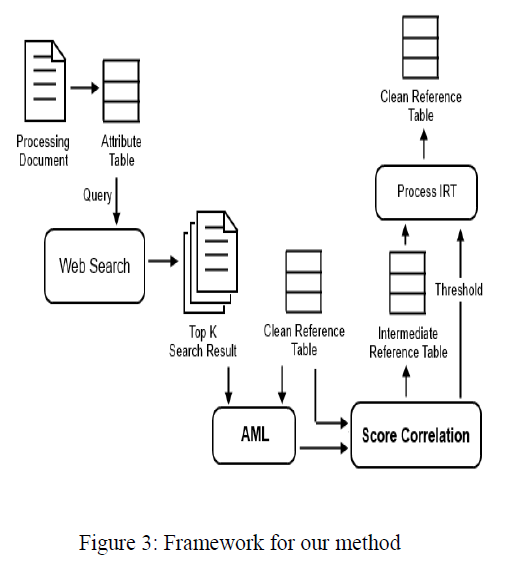
| We propose the project as a web-based join framework which uses a list of elements T with an attribute T:X and a clean reference list R with an attribute R:A, the problem is to create from the web an intermediary table RT containing valued correlations between two attributes T.X and R.A in order to perform a join between T and R. Given that the information available on the web can be dirty and noisy, RT shall contain the likelihood associated with its entries. Based on the hypothesis that there exist web documents containing elements of T.X that also contain the elements of R.A, we use the elements of T.X as a query for a search engine to retrieve the ranked list of documents. |
| First, given that the mention attribute in web pages might not be exact, we need to locate clean references approximately mentioned in given documents, for this AML method is presented second, besides given attribute, some other attributes might also occur in the web pages. To link given attribute with them, we use score correlation. We use Edit Distance Vector which is the simple function for finding the similarity when compare with cosine similarity. Edit Distance Vector reduce the extra complexity in computation because it is secondary step of extraction there is no need of high evaluation. |
ALGORITHMS USED |
| Data mining can be used for extracting previously unknown patterns like groups of data records as well as to extract word and calculate between two data items. The algorithm used to find these dependencies between the data items is AML algorithm, while the algorithm used to extract groups of records is K-means clustering. |
Approximate Membership Localization (AML) Algorithm : |
 |
 |
| The project as a web-based join framework which uses a list of elements T with an attribute T:X and a clean reference list R with an attribute R:A, the problem is to create from the web an intermediary table RT containing valued correlations between two attributes T:X and R:A in order to perform a join between T and R. Given that the information available on the web can be dirty and noisy, RT shall contain the likelihood associated with its entries. Based on the hypothesis that there exist web documents containing elements of T:X that also contain the elements of R:A, we use the elements of T:X as a query for a search engine to retrieve the ranked list of documents Docs. |
| First, given that the mention attribute in web pages might not be exact, we need to locate clean references approximately mentioned in given documents, for this AML method is presented second, besides given attribute, some other attributes might also occur in the web pages. To link given attribute with them, we use score correlation. We use Edit Distance Vector which is the simple function for finding the similarity when compare with cosine similarity. Edit Distance Vector reduce the extra complexity in computation because it is secondary step of extraction there is no need of high evaluation. |
Scoring Correlations: |
| Scoring correlations for each document depends upon three relevant parameters frequency, distance and document importance. |
| Frequency freq: the number of times each reference is mentioned in each document of Docs. |
| Distance dist: the distance between the mention of each clean reference and the position of T:x. |
| Document importance imp: documents retrieved on the web are of different importance w.r.t. their relevance to the query, i.e., their ranks in a web search engine results. |
| The following equation is used to find the score correlation |
 |
P- Pruning: |
| Guarantee that all best match substrings can be found within. For very large reference lists, the number of these window domains, especially overlapped ones, can become an issue. In this section, we introduce how to prune domains that impossible to contain a best match substring, and how to minimize the size of the remaining domains. |
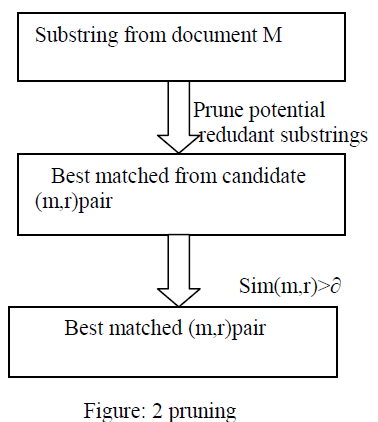 |
| Given an input document M and an entity reference list R, the task of approximate membership localization is to find all match substrings m in M for each reference r in R, such that: |
| 1. sim(m,r), where sim() is a given similarity function, and tow is a given threshold between [0, 1]. |
| 2. there is no substring m’ that overlaps with m in any position of M which satisfies sim(m’, r’)> sim(m, r), where r’ is also a reference from R. |
| M- to denote the input document, R to denote the entity reference list, and Tow-to denote the similarity threshold to the string similarity function sim(a; b), where a and b are two strings |
| We now present the detailed algorithm of PPrune (Potential redundancy prune). Given a reference list R, an Inverted index is built over the words of all references in R and the strong words of each reference are also selected. For a coming document M, we generate window domains from it. Each domain is represented by (posb; pose; r), where posb and pose refer to the starting and ending position of the domain in M, r is the unique reference it corresponds to. All domains are sorted according to their starting positions and stored in a set Dsort. We also use set Dact to store active domains being processed. Starting from the beginning position of M, we do: |
| Step 1: We step to the next new word position poscur, with the word wcur in that position. |
| Step 2: We remove the first domain from Dsort and put it into Dact, until it can’t satisfy Dsort[1].posb= poscur. |
| Step 3: For each domain D =(posb, pose, r) in Dact, if wcur presents in r, it becomes a word in D’s segment, otherwise it becomes a word in D’s interval. The Interval Pruning strategy is applied to all generated intervals. If poscur = D.pose, the Boundary Pruning and Weight Pruning are applied as well. |
| Step 4: If poscur is not included in any range of domains or it already reaches the ending position of M, then the function Locate Best Match is called to generate the best match substrings from all domains in Dact. |
| Step 5: We do step 1 to step 4 iteratively, until poscur reaches the ending position of M. We output all best match substrings we learn. |
WORKING AND RESULTS |
| Over all process is the extracting document without overlap. |
| Data set has been collected from: |
| 1.http://www.cnts.ua.ac.be/conll2003/ner |
| 2.http://tjongkimsang@ua.ac.be |
| 3.http://fien.demeulder@ua.ac.be |
| 4.http://projects.students3k.com/ieee-base-paperand- document-download-on-networkingdomain. html |
| 5.http://ieeeprojectsworld.blogspot.in/2013/09 /toget- abstracts-pdf-base-paper-review.html |
| From our data set we will extract the desire document with efficient manner which support of score correlation and AML algorithm. The stepwise process is below theory, |
| First, To extract the documents from the web using a content based search processed using the given document attributes as query input. Content based document retrieval is process of retrieving a document by search for the given keyword within each document in the document set. We select top K resultant documents from the search results for our next level of processing. Each document contains certain rank value assigned to it based on the content matching the given query attributes. |
 |
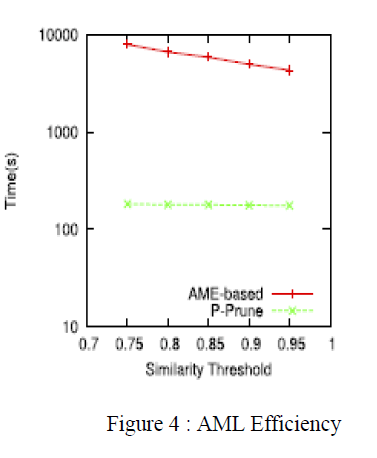
| Secondly, to remove the AML problem from our process this is to extract the clean reference approximately. It uses an optimized P-Prune algorithm, which can prune potential redundant substrings from documents before generating clean reference approximately. This algorithm shows a much higher efficiency than the AME-based algorithm. After the pruning process we use a similarity function for extracting the approximate clean reference from the documents. |
| Thirdly, scoring correlations for each document depends upon three relevant parameters frequency, distance and document importance. The following equation is used to find the score correlation. We use an inverse document based page ranking to assign rank to the documents which enhance the process of scoring correlation. |
| Finally, to construct a reference table by using the results produced by the approximate membership location and score correlation modules. In this step we convert the intermediate reference table to a clean reference table considering its score correlation values. This assigned score value is used as a threshold value to filter out the approximate reference from the intermediate reference list. After that CRT will be display to user what they searching. |
 |
CONCLUSION |
| I formalize the AML problem and to solve it with an efficient P-Prune algorithm. The improvement of AML over AME, we apply both approaches within our proposed web-based join framework, which is a typical real-world application that greatly relies on the results of membership checking. AML-targeted solutions are more appropriate than the AME-targeted solutions for this type of real-world applications, since the matched pair results of the AML are much closer to the true matched pairs than AME result |
References |
|