International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
R.S.Venkatesh1, P.K.Reejeesh1, Prof.S.Balamurugan1, S.Charanyaa2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
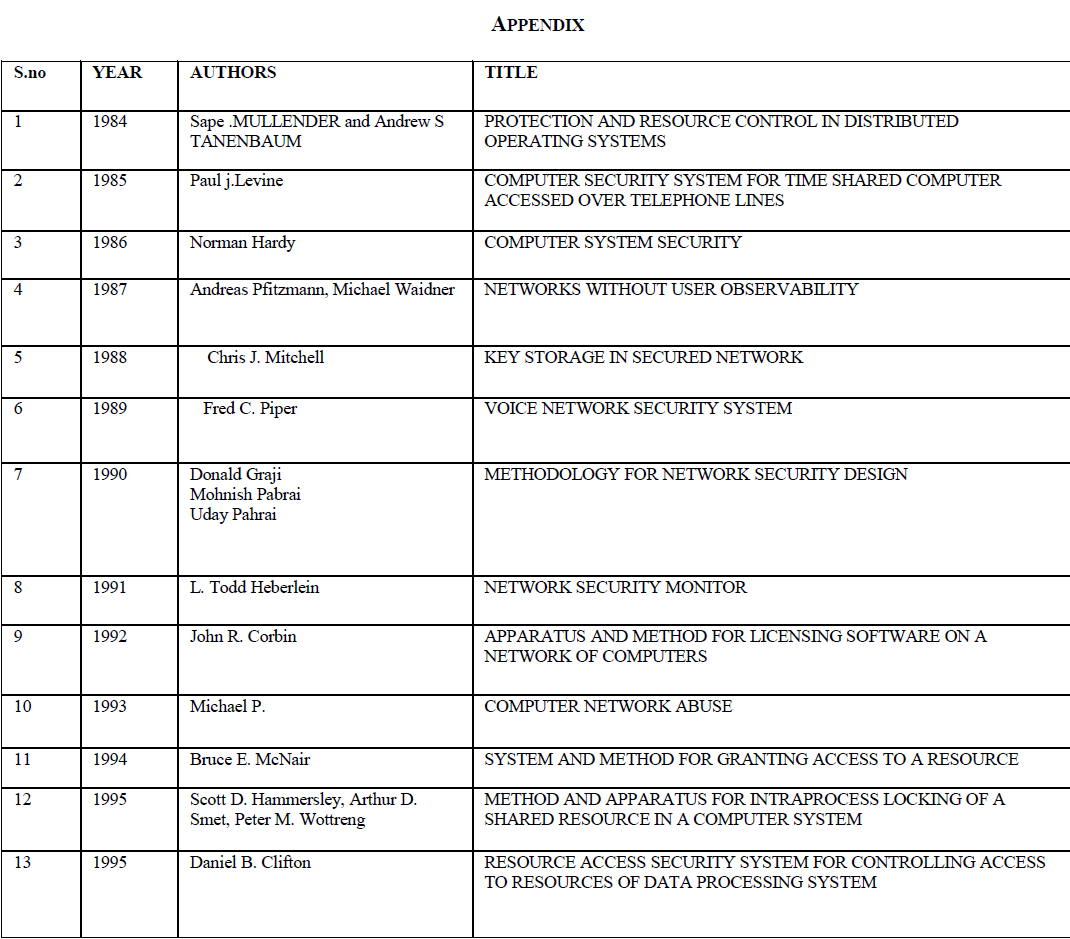
This paper reviews methods developed for anonymizing data from 2004 to 2006 . Publishing microdata such as census or patient data for extensive research and other purposes is an important problem area being focused by government agencies and other social associations. The traditional approach identified through literature survey reveals that the approach of eliminating uniquely identifying fields such as social security number from microdata, still results in disclosure of sensitive data, k-anonymization optimization algorithm ,seems to be promising and powerful in certain cases ,still carrying the restrictions that optimized k-anonymity are NP-hard, thereby leading to severe computational challenges. k-anonimity faces the problem of homogeneity attack and background knowledge attack . The notion of ldiversity proposed in the literature to address this issue also poses a number of constraints , as it proved to be inefficient to prevent attribute disclosure (skewness attack and similarity attack), l-diversity is difficult to achieve and may not provide sufficient privacy protection against sensitive attribute across equivalence class can substantially improve the privacy as against information disclosure limitation techniques such as sampling cell suppression rounding and data swapping and pertubertation. This paper aims to discuss efficient anonymization approach that requires partitioning of microdata equivalence classes and by minimizing closeness by kernel smoothing and determining ether move distances by controlling the distribution pattern of sensitive attribute in a microdata and also maintaining diversity.
Keywords |
| Data Anonymization, Microdata, k-anonymity, Identity Disclosure, Attribute Disclosure, Diversity |
INTRODUCTION |
| Need for publishing sensitive data to public has grown extravagantly during recent years. Though publishing demands its need there is a restriction that published social network data should not disclose private information of individuals. Hence protecting privacy of individuals and ensuring utility of social networ data as well becomes a challenging and interesting research topic. Considering a graphical model [35] where the vertex indicates a sensitive label algorithms could be developed to publish the non-tabular data without compromising privacy of individuals. Though the data is represented in graphical model after KDLD sequence generation [35] the data is susceptible to several attacks such as homogeneity attack, background knowledge attack, similarity attacks and many more. In this paper we have made an investigation on the attacks and possible solutions proposed in literature and efficiency of the same. |
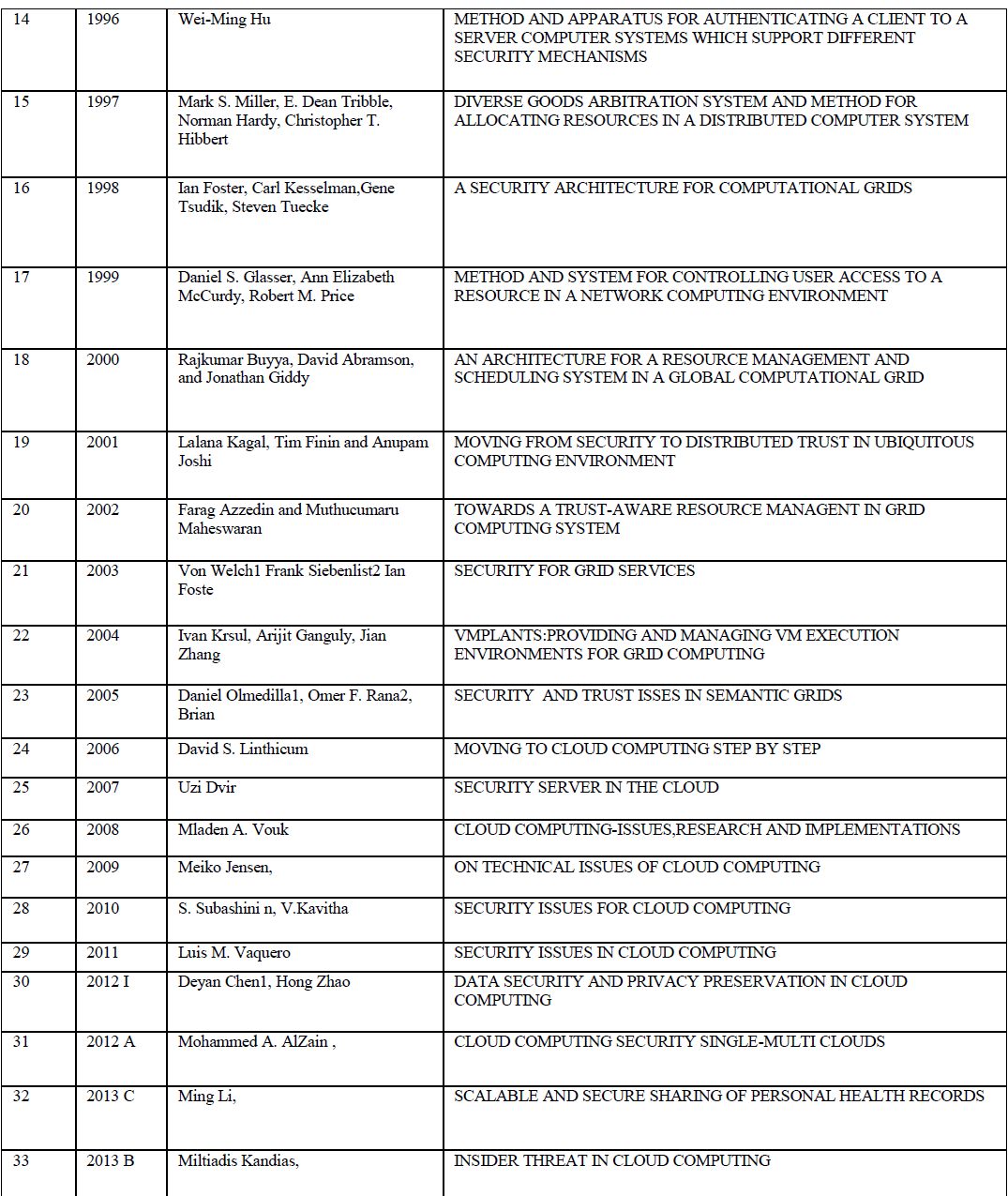
VM PLANTS: PROVIDING AND MANAGING VIRTUAL MACHINE EXECUTION ENVIRONMENTS FOR GRID COMPUTING – 2004 |
| VM - Virtual Machine plants provide a reliable and flexible environment for problem solving in a grid computing systems. Service oriented architecture is employed to represent VM plant middle for providing VM customization and efficient cloning. |
| The main objective of this architecture is to provide flexibility, fast VM instantiation, scalability, resilience to failures and interoperability. Flexibility is obtained by applying the cloning process onto various VM technologies. Interoperability is achieved by using efficient cloning mechanisms. |
| Every users and resource providers select a unique service for distributed computing in VM plant architecture. A “classic” Virtual Machine has the ability to run on different OS. It provides isolation and security mechanisms; supports customization and encapsulation; provide support for legacy applications. |
| The VM plant architecture works on the basis of services provided within web and grid frame works. The client communicates with the service through VMshop. The service then makes use of standard mechanisms to create a new virtual machine. The client cannot directly access the VM plants. The new instantiated VM’s are used for accessing VM plants. The VMshop can provide secure access to resources; configuring network; gives resources access information; supports query handling. |
| VM plant uses “Production Process Planner” (PPP) for the process of creating new Virtual Machine. The PPP after receiving a request, selects an exact VM from the VM warehouse. VM information system gives information about currently used machines. VM monitor is used to update the VM information system. |
| Once the exact Virtual Machine is selected, it has to satisfy the following tests. |
| i. Subset test |
| ii. Prefix test |
| iii. Partial test |
| After this the Virtual Machine is cloned using VM Production Line. Then the VM should parse on several configuration processes. After cloning and configuration processes are completed, the virtual workspace is combined with n IP address. The cloning and configuration techniques are used for describing the feasibility of the VM. VM Plants architecture is efficient for instantiation of VM clones and flexible for producing new services. |
SECURITY AND TRUST ISSUES IN SEMANTIC GRIDS – 2005 |
| A large scale distributed computing system such as “Grid computing” should have the ability to allow sharing of resources over a “Virtual Organization” (VO). Recently, the Grid Security Infrastructure (GSI) possesses a trust relationship between Grid Computers. But still there are no suitable methods for authentication and authorization. Even they do not have the ability to select a “trustworthy” user. |
| “Access Control” is enhanced using Property based authorization mechanisms, automatic certification, bidirectional & iterative security negotiations and policy based authorization. The “Trust Management” includes two basic approaches. |
| i. Policy - based trust management. |
| ii. Reputation – based trust management. |
| The Policy - based trust management reveals certain rules, standards and policies to identify whether a user is “trustworthy” or “untrustworthy”. The Policy - based trust management is responsible for taking access control decisions. The system which posses Policy - based trust makes use of semantics for making decisions. |
| The Reputation – based trust management concentrates on public - key certificates, P2P system, mobile ad – hoc network and semantic web. |
| A user to access a resource must satisfy some of the following security mechanisms. |
| i. Proxy certificates signed by a Certification Authority. |
| ii. Identity based authorization. |
| iii. Simple authentication/authorization. |
| iv. Manual credential fetching. |
| A term called “Community” is introduced in which all the users can communicate with each other efficiently. The introduction of these communities will decrease the cost of interaction. Communities can be formed either implicitly or explicitly. There are four phases in which a trust is achieved in virtual organization. |
| i. Service provider identification – determines VO objectives. |
| ii. Formation and service provider invitation – compute community trust and provision resources. |
| iii. Operation and service provider interaction – trust based service invocation. |
| iv. Dissolution – terminates the resources. |
| In Grid Computing, the security and trust issues in a Virtual Organization is computed using policy – based and reputation – based trust management approaches. The basic idea of this paper is to point out the restrictions of resources and access control protection mechanisms seen in Grid Computing. |
MOVING TO CLOUD COMPUTING STEP – BY – STEP – 2006 |
| Cloud computing is the extension of SOA which provides resources such as Storage – as – service, Data – as – a – service and platform – as – a – service. The logic is to identify which cloud service can be adopted for the exiting SOA. |
| A cloud is organized with the help of following services. |
| i. Testing – as – a – service |
| ii. Management – as – a – service |
| iii. Application – as – a – service |
| iv. Process – as – a – service |
| v. Information – as – a – service |
| vi. Database – as – a – service |
| vii. Storage – as – a – service |
| viii. Infrastructure – as – a – service |
| ix. Platform – as – a – service |
| x. Integration – as – a – service |
| xi. Security – as – a – service |
| Security and performance are observed as barriers in cloud. However, cloud does not support all the computing resources. The cloud computing is suitable for cases where |
| i. Applications, processes and data are independent. |
| ii. New applications are used. |
| iii. Web – based platform is used. |
| iv. Core internal enterprise architecture should be good. |
| Cloud computing is not suitable when |
| i. Processes, applications and data are coupled. |
| ii. High security is needed. |
| iii. Application is legacy. |
| iv. The points of integration are not well defined. |
| The cloud architecture describes about the |
| i. Business drivers. |
| ii. Information under management. |
| iii. Existing services under management. |
| iv. Core business processes. |
| There are several steps involved in the process of creating cloud. They are |
| i. Access the business. |
| ii. Access the culture. |
| iii. Access the value. |
| iv. Understand your services, processes, data and cloud resources. |
| v. Identify candidate data, services and processes. |
| vi. Create a governance strategy and security strategy. |
| vii. Bind candidate services to data and processes. |
| viii. Relocate services, processes and information. |
| ix. Implement security, governance and operations. |
CONCLUSION AND FUTURE WORK |
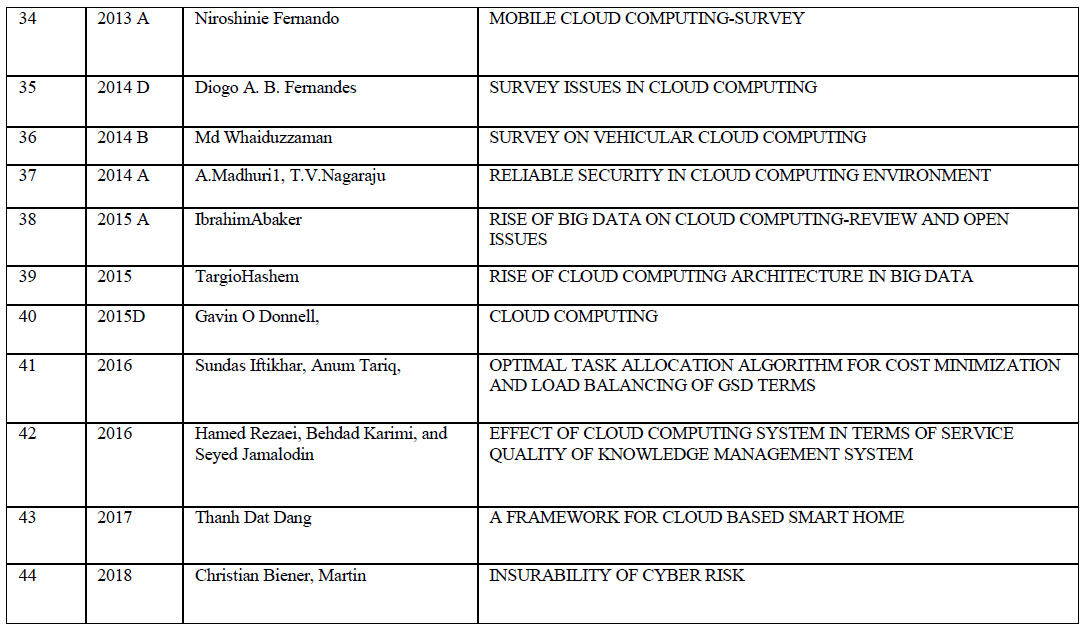
| Various methods developed for anonymizing data from 2004 to 2006 is discussed. Publishing microdata such as census or patient data for extensive research and other purposes is an important problem area being focused by government agencies and other social associations. The traditional approach identified through literature survey reveals that the approach of eliminating uniquely identifying fields such as social security number from microdata, still results in disclosure of sensitive data, k-anonymization optimization algorithm ,seems to be promising and powerful in certain cases ,still carrying the restrictions that optimized k-anonymity are NP-hard, thereby leading to severe computational challenges. k-anonimity faces the problem of homogeneity attack and background knowledge attack . The notion of ldiversity proposed in the literature to address this issue also poses a number of constraints , as it proved to be inefficient to prevent attribute disclosure (skewness attack and similarity attack), l-diversity is difficult to achieve and may not provide sufficient privacy protection against sensitive attribute across equivalence class can substantially improve the privacy as against information disclosure limitation techniques such as sampling cell suppression rounding and data swapping and pertubertation. Evolution of Data Anonymization Techniques and Data Disclosure Prevention Techniques are discussed in detail. The application of Data Anonymization Techniques for several spectrum of data such as trajectory data are depicted. This survey would promote a lot of research directions in the area of database anonymization. |
 |
 |
 |
References |
|