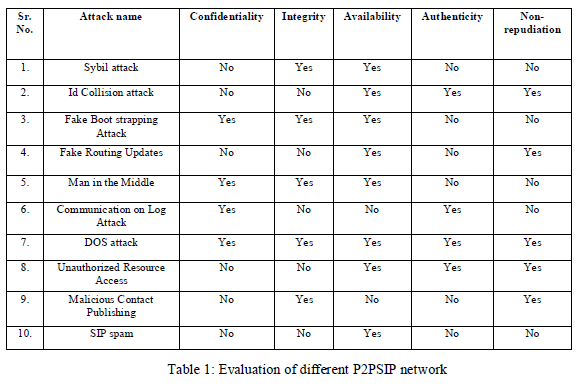
International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| Prof. Sonawane Vijay Ramnath 1, Ratnaparkhi Punam Sharad 2, Patil Snehal Subhash 3 Associate Professor, Dept. of Information Technology Engineering, Amrutvahini College of Engineering And Research Centre, Sangamner, Maharashtra, India, India 1 M.E. student, Dept. of Information Technology Engineering, Amrutvahini College of Engineering And Research Centre, Sangamner, Maharashtra, India 2 M.E. student, Dept. of Information Technology Engineering, Amrutvahini College of Engineering And Research Centre, Sangamner, Maharashtra, India 3 |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Most of the Users often would like to retain past versions of XML documents, for several reasons. Reason might be, those past versions may contain useful historical information. Second, various laws require that for data that appear in financial reports drawn from prior versions, that those versions be retained for a stated period of time . Retaining data or document have challenging part is to keep them in consistent state, that is preserving integrity of the data or document. To preserve integrity means to preserve the constraints such as identity, referential integrity, cardinality, & data type. This can be possible by implementing the concept temporal schema & temporal document which can vary over the valid as well as transaction time. We do this by just replacing schema with temporal schema & replacing document by temporal document which are upward compatible with conventional XML & conventional tools, which we are extended to support the temporal constraint.
Keywords |
| Constraint; Referential integrity; Unique; Cardinality |
INTRODUCTION |
| As with number of different types of documents, spreadsheets, presentations, and data in a database, XML documents also are changed over time. XML is very popular language for document and data & having two different orientation document centered & data centered, here in both the cases schema is important. Schema defines the building blocks of an elements. Users often would interest to retain past versions of XML documents, for the Reasons such as to get past versions which may contain useful historical information. Also various laws require that for data that appear in financial reports drawn from prior versions, that those versions be retained for a stated period of time Retaining data or document have challenging part is to keep them in consistent state that is preserving integrity of the data or document. As XML is it belongs to dynamic exchange of information it thus becomes important to retain prior versions of an XML document. So while taking advantage of older version, it is prior to know what would be the integrity constraint held on that document & how we can generalize them so that they can new version given the existence of such prior versions. In this paper we consider how to accommodate and validate time varying data within XML schema, previous novel approaches was concern with retaining the non temporal XML schema for document, which utilizes series of separate schema document to achieve data independence. In this paper we convert element into temporal element type by providing temporal annotation in type definition. |
| Motivational example: |
| John's father officially reported birth on April 4, 1975. This means that a Smallville official inserted the following entry in the database on this date: Person (John Doe, Smallville) Note that the date itself is not stored in the database. After graduation John moves out, but forgets to register his new address. John's entry in the database is not changed until December 27, 1994, when he finally enters Bigtown's city hall. A Bigtown official updates his address in the database. The Person table now contains Person (John Doe, Bigtown) Note that the information of John living in Smallville has been overwritten. There is no way to retrieve that information from the database. Any official accessing the database on December 28, 1994 would be told that John lives in Bigtown. More technically: if a computer scientist ran the query SELECT ADDRESS FROM PERSON WHERE NAME='John Doe' on December 26, 1994, the result would be: Smallville. Running the same query 2 days later would result in Bigtown. Until his death the database would state that he lived in Bigtown. On April 1, 2001 the coroner deletes the John Doe entry from the database. Running the above query would return no result at all. Assume that the history of the john is described in an XML document called biography.xml .The document has information about the john from his birth to his death. Over time the document is edited to add information about each new year of john‟s life to revise incorrect information as well as to add new information. Assume that information about john is as follows : |
 |
| 1) |
| ... |
| <author> |
| < birth_detail >john doe born in america </ birth_detail > |
| </author> |
| ... |
| Listing 1. Fragment of biography.xml on 3 April 1975 |
| 2) |
| <author> |
| < birth_detail >john doe born in america </ birth_detail > his father registered |
| his birthdate officially |
| <livein> Smallville </livesin> |
| </author> |
| ... |
| Listing 2. John's father officially reports John's birth on 4 April 1975 |
| A time-varying document records a version history, which consists of the information of each version, along with the timestamps indicating the lifetime of that version. Figure 2 shows a fragment of the time varying document that captures the history of john Doe. Each edit results in only a small, and there will be localized change to the document. In Figure 3 the transaction-time lifetimes of each element are represented with an optional. |
| 3) |
| ... |
| <author_RepItem> |
| <author_Version> |
| <tv:timestamp_TransExtent begin="1975-04-03" end="1975-04-04"/> |
| <author> |
| <birth_detail>john doe born in america </ birth_detail > |
| </author> |
| </author_Version> |
| <author_Version> |
| <tv:timestamp_TransExtent begin="1975-04-04" end="1994-8-26"/> |
| <author> |
| < birth_detail >john doe born in america </birth_detail > his father registered |
| his birthdate officially |
| <livein> Smallville </livesin> |
| </author> |
| </author_Version> |
| ... |
| Listing 3. Snippet of a Temporal Document |
| Keeping track of history is useful for retaining data But it also changes the nature of validation against a schema. Assume that the file winAuthor.xsd contains the snapshot schema forbiography.xml. The snapshot schema is the schema for an individual version. A fragment of the schema is given in listing 4. Note that the schema describes the structure of the fragment shown in Listing 1, listing 2. The important problem is that although individual versions conform to the schema, the time-varying document does not. So winAuthor.xsd cannot be used (directly) to validate the time-varying document of Listing 3. |
| 4) |
| ... |
| <element name="author"> |
| <complexType mixed="true"> |
| <sequence> |
| <element name=" birth_detail " type="string"/> |
| <element ref="livein" minOccurs="1" maxOccurs="unbounded"/> |
| <element name="birthPlace" type="string" minOccurs="0" |
| maxOccurs="1"/> |
| </sequence> |
| <attribute name="age" type="nonNegativeInteger" use="required"/> |
| </complexType> |
| </element> |
| ... |
| Listing 4. winAuthor.xsd |
| It is always expensive to validate version, especially when the amount of versions are greater .The schema for a timevarying document should take into account the elements (and attributes) and their associated timestamps. This new generated schema is called representational schema keeping track of versions it also uses conventional XML schema validator tool for validating the document. Now to define a new schema, schema language might needed new way to express it all. There is no mechanism for reasoning about timestamp, no existing technique to automatically get representational schema, hence improved tool is needed for validating time varying information. Here we use schema versioning which provide the intelligent solution to handle temporal mismatch between data and its information. |
II. DESIGN IMPLEMENTATION |
| We first summarize briefly the design of _XSchema. We start with some relevant terminology. |
| Conventional Document: An XML document that has no temporal aspects. At a minimum, |
| Temporal Document: An XML document that represents a sequence of conventional documents (i.e., slices). It has the root element <temporalRoot> |
| Conventional Schema: An XML Schema document that describes the structure of the conventional document(s). The root element is <schema>. |
| Slice: A version of a temporal document at a given point in time. For example, if a temporal document is comprised of two conventional documents d1 and d2, which occur at times t1 and t2, respectively, then the slice at time t2 is d2 |
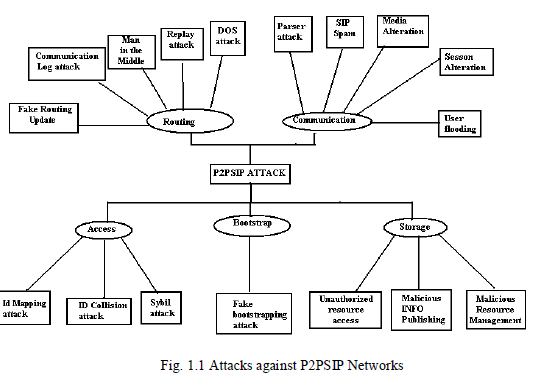 |
| Fig.1. Overall Architecture of τXSchema |
| Figure tells interaction between temporal schema and its constituent conventional schema. This scenario can be more clear with following example, suppose there is need to edit the information about any organization, so when it comes to point out editing , it ultimately generates the new updated version , nothing but sequence of conventional documents, Let us consider there may be 4 documents, first one is original & other three are new versions of it. Now the most specific difficulty arise at version mount time, and to manipulate versions easily user need to define Temporal Schema associated with base schema as one of the component. Like base schema there is also need of 2 more components nothing but logical annotation and physical annotation.Logical annotation tells variety of characteristics such as whether lifetime describes as a single event or certain times etc. Physical annotation tells time stamp representation option selected by user , i.e. where the physical timestamp will be placed. Temporal schema ties both physical and logical annotation together, that document contains sub elements associated with conventional schema, logical & physical annotation along with time span during association was in effect. Figure also shows tool SQUASH which makes temporal document consistent i.e. timestamp is spread out across the document associated with versions of elements. Which avoids redundancy. Tool SCHEMAMAPPER represents schema generated automatically from temporal schema, which describes the versions of temporal document. Base Schema contains following constraint cardinality constraints, uniqueness constraint, referential integrity. These all constraint will be apply into temporal document as well as new additional restriction can also specify in it. So that this TXSchema is use to augment conventional schema with additional logical annotation, XMLLINT is a tool for validating document against schema. |
III. THEOROTICAL FRAMEWORK |
| A. Types Of XML Schema Constraints |
| There are 4 types of constraint on XML Schema that need to keep in track 1) Data type Constraints : Suppose the fact that the name attribute is a string, then it applies equally in the static and temporal context , in this situation the content of name will change during the period of time but type never. |
| 2) Cardinality constraints: The cardinality of any set is a measure of the “number of elements of the set” e.g. A= {1.3.4}, so cardinality of A is 3. In cardinality issues of MinOccurs & MaxOccurs matters lot, & default value of it is set to 1. Example : there can be multiple <emp> subelement within <emps>, there can be only 1 <SSN> within <emp> Cardinality restricted to use to optional or required. |
| 3) Identity constraints: It restricts uniqueness of element and attribute in document, for this we can define key or unique constraint. It prohibits singularity of Parts and attributes in an exceedingly given document. Like the relative model, XML Schema permits users to outline each key and unique constraint. The excellence between these 2 ithat the key constraint doesn't permit a null price in any of the element fields , whereas missing (null) values don't lead to a violation of the distinctive constraint. We can define it in both the way sequenced and non sequenced . For temporal document D= (X,T,S,A) the identity constraint is sequenced if and only if for all items t € T, if c is a node of type E in X t= slice(t,D) It says that two elements can evaluate to the same key value if and only if they are in fact the same element. |
| A nonsequenced <unique> or <key> constraint is specified in the logical annotation through one of the following element : <nonSeqUnique>, <nonSeqKey>,or <uniqueNullRestricted>. The subelement and attributes of these nonsequenced constraints are provided in table 2There are 4 types of constraint on XML Schema that need to keep in track. |
 |
| A nonsequenced <unique> constraint requires that the field value combination of the constrained element is unique between items across time. Non sequence constraint can be used in 3 ways : Between : suppose if the non sequenced unique constraint is on email and evaluation window is year. |
 |
| Within : if somebody says employee cannot switch from 1 empid to another then he can use within, the scope of the expression is within |
 |
| Listing 6. Non-seq. constraint “within” each employee |
| Between & within : |
| This semantic will apply when each emp id is unique and cannot reuse email. A conventional identity constraint does not imply nonsequenced uniqueness (it only implies that there are no duplicates in a slice). Thus, the same product No (a conventional key) can be reused for another product or changed between slices |
| 4) Referential Integrity : It refers to concept of relational database also it refers valid key or unique constraint . Example <keyref> ensures that only valid product numbers are entered for an order. Each referential integrity constraints leads to a sequenced counterpart in a temporal document |
| B. Classes Of Semantics |
| The XML Schema constraints are snapshot constraints since they are restricted to a specific snapshot document. These constraints need to be augmented for τXSchema. The time frame over which a constraint is applicable classifies it into one of two types, either sequenced or non-sequenced. A temporal constraint is sequenced with respect to a similar snapshot constraint in the schema document, if the semantics of the temporal constraint can be expressed as the semantics of the snapshot constraint applied at each point in time. A constraint is non-sequenced if it is applied to a temporal element as a whole (including the lifetime of the data entity) rather than individual time slices. Given a snapshot XML Schema constraint, we define the corresponding temporal semantics in τXSchema in terms of a sequenced constraint. For example, a snapshot ( constraint (cardinality) , “There should be between zero and four website URLs for each contractor,” has a sequenced equivalent of: “There should be between zero and four website URLs for each contractor at every point in time.” Non-sequenced constraints are not defined based on snapshot XML Schema equivalents. An example of a non-sequenced (cardinality) constraint is: “There should be no more than ten website URLs for each supplier in any year.” Non-sequenced constraints are listed in the temporal annotations document. In a few cases (when we extend a particular XML Schema constraint for additional functionality), sequenced constraints are also listed in the temporal annotations document. Technical Report document [2] further discusses the sequenced and non-sequenced temporal annotations to the XML schema constraints in detail. Special kind of sequenced constraint is a current constraint apply at current point in time. |
| C. Temporal data Model : |
| An XML document is usually modeled as a labeled tree & The temporal XML document modeled as a time stamped set of XML document |
| Definition of temporal XML model : |
| A temporal XML model is a tuple having attributes (X,T,S,A) |
| 1) X is a set of XML data model instances where an instance Xi= (Vi, Ei) Vi is a set of node (element) Ei is a set of attributes of element |
| 2) T is a set of times. |
| 3) S : X→2 T is a timestamp function which maps XML data model instance to a timestamp for which it is current in the time dimension. |
| 4) A : v→v is temporal association relation that associates a node in some XML Data. |
| The slice function extracts a slice from a temporal document. |
| Definition of Slice : |
| D= (X,T,S,A) be an instance of a temporal XML model. Then for t € T, slice(t,D) = Xi, where Xi € X and t € S(Xi). |
| D. Items : |
| In order to validate nonsequenced constraint, it is necessary to identify which elements persist across various transformations, Of the document. When elements are temporally associated, an item is created. An item is collection of XML elements that represent the same real world entity.An item could be varying with gaps which means that it might be present in some slices and absent in others An item could be varying without gaps i.e. it must exist through consecutive slices only. Another possibility of existence of an item is Constant, i.e. item either always present or never present. Content of an item can pursue one of the 3 alternative constraint mentioned above2. |
IV. TOOLS AND ALGORITHM |
| Our three-level schema specification approach enables a suite of tools operating both on the schemas and the data they describe. This section gives an overview of the suite of tools and the algorithms used by them. The tools are open-source and beta versions are available [2]. The tools have been implemented in Java using the DOM API [3]. The DOM API was chosen over SAX API due to its ability to create an object-oriented hierarchical representation of the XML document that can be navigated and manipulated at the run-time. The primitives explained below use this ability of the DOM API to easily manipulate the document-tree.We first describe the details of the implementation primitives pushUp, pushDown and coalesce. These primitives are used by τVALIDATOR, SQUASH, UNSQUASH, and RESQUASH tools for manipulating XML trees. SCHEMA MAPPER, a logical-to-representational mapper, is introduced next. This tool takes as input the snapshot schema, temporal and physical annotations and generates a representational schema. This representational schema is used by τVALIDATOR to validate the given temporal document using a conventional XML Schema validator. τVALIDATOR does the actual temporal schema and data validation.Temporal data validation is a several-step process, a major part of this process being gluing elements to form items. The items are then validated individually. Other tools in the suite squash, unsquash and resquash the documents. Given a temporal schema (bundle) and a set of snapshot documents, SQUASH combines all of the snapshot documents into a single temporal document. UNSQUASH performs the opposite operation, breaking the single temporal document into multiple snapshot documents. RESQUASH is just a combination of UNSQUASH and SQUASH; given a temporal document, an old physical annotation and a new physical annotation, RESQUASH changes the representation of the given document as per the new physical annotation. |
| A. Implementation |
| Primitives As mentioned earlier, the temporal and physical annotations are orthogonal in nature; a user can change the location of timestamps, independent of specifying the temporal characteristics of a particular element. The representation of the temporal document will change accordingly. Thus, two documents having a single temporal annotation can have different physical annotations and hence different representations. While processing a temporal document, one of the most frequently needed operations on the temporal document moves the timestamps up or down in the hierarchy of XML elements defined by original snapshot schema. Another operation needed by both τVALIDATOR and SQUASH utilities coalesces the adjacent versions from a given item. We decided to write primitive functions for these operations so that they could be reused for building the tools with minimum efforts. We now describe the primitive functions representing these operations |
| 1) The pushUp Function:Although temporal and physical annotations are orthogonal in nature, one restriction on the physical annotation is that, at least a single timestamp should be located at or above the topmost temporal element in the XML schema hierarchy. If a given physical annotation has timestamps at locations other than the temporal elements, the pushUp function moves the timestamps up in the hierarchy after coalescing the items Other helper functions used in the algorithm are as follows. |
| • isItem (e): The function checks whether the given XML element e has a representation of an item. |
| • createItem (e, timePeriod): The function creates a new XML element with the representation of an item and adds the given element e as the (single) version of newly create item with the time period of the version being timePeriod |
| • replace (src, target): The function replaces the src element with the target element. |
| • getTimePeriod(itm): The function returns the complete time-period of an item. i.e., The time-period with start time equal to the start time of the first version and end time equal to the end time of the last version of an item. |
| 2) The pushDown Function: The pushDown function behaves exactly opposite of the pushUp function. If a given physical annotation has timestamps at locations above the temporal elements, the pushDown function moves these timestamps down the hierarchy. After executing this function on the temporal document, timestamps will be located at the temporal elements. At this point, since the temporal characteristics and the representation coincide, it becomes easier to perform coalescing on the resultant temporal document. |
| Other helper functions used in the algorithm are as follows. |
| • isTimeVarying (itm, temporalAnnotation): The function returns true if itm definition is present in the temporal annotation. |
| • versionCount (itm): The function returns the number of versions present in the given itm element. |
| • GetVersion (itm, n): The function returns the nth version of the given itm element. |
| 3) The coalesce Function :As explained in Section 6, elements in two snapshots of a temporal XML document can be temporallyassociated. If the elements are DOM-equivalent and the snapshot periods are contiguous, those two elements could be replaced by a single element with the time period extending from the start time of the first element to the stop time of the last element. This process is termed coalescing and is an integral part of SQUASH to compact the document. |
| B. Schma Mapper |
| Once the annotations are found to be consistent, the logical-to-representational mapper generates the representational schema from the original snapshot schema and the temporal and physical annotations. The representational schema is needed to serve as the schema for a time-varying document/data. Once the annotations are found to be consistent, the logical-to-representational mapper generates the representational schema (box 10) from the original snapshot schema and the temporal and physical annotations. The representational schema is needed to serve as the schema for a timevarying document/data (box 9). The time-varying data can be created in four ways: |
| • Automatically from the non-temporal data using SQUASH tool. |
| • Automatically from the data stored in a database, i.e., as the result of a “temporal” query or view. |
| • Automatically from a third-party tool, or |
| • Manually. |
| Every time-varying element is given a timestamp for the valid time and/or the transaction time as appropriate. Nontemporal elements and attributes are translated as is. The process of converting a snapshot schema into the representational schema is explained in the next few paragraphs. |
V. IMPLEMENTATION TECHNOLOGY |
| τVALIDATOR and different tools are written in Java and are developed victimization Java a pair of, Standard Edition, v1.4. They use W3C specifications arthropod genus for parsing the XML documents, building DOM trees and process XPath expressions. „W3C DOM API‟ is employed for parsing the XML documents. „XML Path Language (XPath) Specification Version one.0‟ is employed for process XPath expressions. Third party implementations of those arthropod genus from Apache computer code Foundation accessible as a part of Apache XML project [2] were used. the small print of those implementations area unit given below. |
| • XERCES, a section of the Apache XML project may be a family of computer code packages for parsing and manipulating XML documents. Xerces provides each XML parsing and generation. Xerces provides the implementation for the W3C DOM API. The implementation is accessible underneath „Apache computer code License‟ and is accessible freely [4]. |
| • XALAN, a preferred open supply computer code library from the Apache computer code Foundation, is used as an implementation of XPath API. It implements the XSLT XML transformation language and therefore the XPath XML command language. The implementation is accessible underneath „Apache computer code License‟ and is available freely In order to support bitemporal information, we have a tendency to anticipate following fine arts and implementational changes to the prevailing tools. |
| SCHEMAMAPPER : SCHEMAMAPPER would want little or no amendment. because the illustration of a temporal document goes to stay constant, it has to add each group action and valid-time parts from the TVSchema for the weather from physical annotation that area unit time-varying on each the dimensions. |
| τVALIDATOR : τVALIDATOR would conjointly want very little amendment to support bitemporal information. Since the illustration of things in an exceedingly XML document isn't getting to amendment, the gluing procedure, that is that the first part of the τVALIDATOR formula, would stay constant. Next step is to validate the individual items identified throughout gluing. within the existing Item category, the validation procedure for the item desires to be extended to perform the validation of things varied on each valid and group action time. |
| SQUASH : To perform squashing of bitemporal information we have a tendency to anticipate a necessity of a wrapper category, e.g., DoBitemporalSquashi to the prevailing design. This category would use the prevailing DoSquashing category to perform the squashing of documents on valid-time for identified transaction-time periods. this can generate the series of temporal documents, which can act as shot documents for squash on transactiontime. the prevailing DoSquashing category and different primitive functions won't be ready to handle these temporal documents, since they weren't designed anticipating the existence of things within the shot documents. therefore the DoSquashing category would want some changes to handle these documents. Also, though the abstract algorithms for the primitive functions remains constant, some implementation level changes would be required. the prevailing Item category has the support for bitemporal time. however the coalescing formula handles solely time-periods. It doesn't handle regions. the present coalesce perform desires Associate in Nursing extension to perform coalescing of regions. |
| UNSQUASH : UNSQUASH tool would conjointly want some changes the same as the SQUASH tool. a brand new wrapper category (e.g., DoBitemporalUnSquashing) may well be other. This category would first unsquash the given bitemporal document on the transaction-time dimension to grant multiple temporal documents on valid-time. every of those documents have to be compelled to be unsquashed on the valid-time dimension giving multiple shot documents. Existing UnSquash would work with none changes for performing arts unsquashing on the valid-time dimension. Some modifications would be required to UnSquash category to perform the unsquashing on the transaction-time dimension. Thus, though the tools would be supported the prevailing categories, addition of some new categories and modifications to the primitive functions would be necessary so as to supply the support for bitemporal data. |
VI. CONCLUSION |
| In this paper we've thought-about the way to accommodate and validate time-varying information at intervals XML Schema. we've given Temporal XML Schema (τXSchema), that is Associate in Nursing extension of XML Schema, infrastructure, and a collection of tools to support the creation and validation of time-varying documents, while not requiring any changes to XML Schema. τXSchema provides Associate in Nursing efficient thanks to define temporal component types; specifically, a part kind which will vary over time, describes the way to associate temporal parts across snapshots, and provides some temporal constraints that loosely characterize however a temporal component will modification over time. Our style conforms to W3C XML Schema definition and is constructed on prime of XML Schema. Our approach ensures information independence by separating (i) the exposure schema document for the instance document, (ii) info regarding what portion(s) of the instance document will vary over time, and (iii) wherever timestamps ought to be placed and exactly however the time-varying aspects ought to be diagrammatic. Since these 3 aspects ar orthogonal, our approach permits every facet to be modified severally. This three-level schema specification approach is exploited in supporting tools; many new, quite helpful tools τVALIDATOR, SCHEMAMAPPER, SQUASH, UNSQUASH, and RESQUASH ar introduced that need the logical and physical information independence provided by our approach. in addition, this independence allows existing tools (e.g., the XML Schema validator, XQuery, and DOM) to be employed in the implementation of their temporal counterparts. we've then extended τXSchema to support schema versionoing. we have a tendency to showed however schema versioning is integrated with support for time-varying documents in a very fashion consistent and upwardly-compatible with XML, XML Schema, and standard XML validators. Schema versioning in its full generality is supported, together with (timevarying) schemas that embody or reference alternative (time-varying) schemas. In doing thus, we have a tendency to leveraged each standard XML Schema and connected tools (principally, the standard validator), yet as τVALIDATOR for information versioning. |