International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
M. Jyostna Grace1 and K. Subhashini2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
Image binarization plays a vital role in text segmentation which is used in OCR application. Binarization of text in degraded images is a challenging task due to the variations in colour, size, and font of the text and the results are often affected by complex backgrounds, different lighting conditions, shadows and reflections. A robust solution to this problem can significantly enhance the accuracy of scene text recognition algorithms leading to a variety of applications such as scene understanding, automatic localization, navigation, and image retrieval. In this paper, we propose a novel method to extract and binarize text from images that contains complex background. We use an Independent Component Analysis (ICA) based technique to map out the text region, which is inherently uniform in nature, while removing shadows, specularity and reflections, which are included in the background. This algorithm works better on images with different degradations. We implement our method on DIBCO dataset then we compare our robust algorithm with state-of-art criteria like binarization based on Otsu method and we can prove that our algorithm will give better results.
Keywords |
| Image binarization,thresholding,adaptive local image contrast, connected components, Independent Component Analysis. |
INTRODUCTION |
| In the recent years, content-based image analysis techniques have received more attention with the advent of various digital image capture devices. The images captured by these devices can vary dramatically depending on lighting conditions,reflections, shadows and specularities. These images contain numerous degradations such as uneven lighting, complex background, multiple colors, blur etc. We propose a method for removing reflections, shadows and specularities in natural scene text images and extracting out the text from a single image. There are many algorithms that aim at extracting foreground text from background in images but thresholdingremains one of the oldest form that is used in many image processing applications. Many sophisticated approaches often have thresholding as a preprocessing step. It is often used to segment images consisting of bright objects against dark backgrounds or vice versa [1], [3], [4]. It typically works well for images where the foreground and background are clearly defined. For color thresholding images, most algorithms convert the RGB image into grayscale but here we will make use of the RGB channel as three different sources. |
| Traditional thresholding based binarization can begrouped into two categories: the one which uses global threshold for the given images like Otsu [2], Kittler et al. [5] and the one with local thresholds like Sauvola [6], Niblack [9]. In global thresholding methods [2], [7], global thresholds are used for all pixels in image. These methods are fast and robust as they use a single threshold based on the global histogram of the gray-value pixels of the image. But they are not suitable for complex and degraded scene images. Also selecting the right threshold for the whole image is usually a challenge because it is difficult for the thresholding algorithmto differentiate foreground text from complex background. On the other hand, local or adaptive binarization [8] methods changes the threshold over the image according to local region properties. Adaptive thresholding addresses variations in local intensities throughout the image. In these methods, a pre-pixel threshold is computed based on a local window around each pixel. Thus, different threshold values are used for different parts of the image. These methods are proposed to overcome global binarization drawbacks but they can be sensitive to image artifacts found in natural scene text images like shadows, specularities and reflections. Mishra et al [13] has recently formulated the problem of binarization as an MRF optimization problem. The method shows superior performance over traditional binarization methods on many images, and we use it as the basis for our comparisons. However, their method is sensitive to the initial auto seeding process. Zhou et al [14] also addresses the segmentation problem in text images which contains specular highlightsand focal blur. On the other hand, we propose a method that removes shadows, specularity and reflections and thus produces a clean binary images even for the images with complex background. The primary issue related to binarizing text from scene images is the presence of complex/textured background. When the background is uneven as a resultof poor or non-uniform lighting conditions, the image will not be segmented correctly by a fixed gray-level threshold. These complex backgrounds vary dramatically depending on lighting, specularities, reflections and shadows. The above methods applied directly to such images give poor results and cannot be used in OCR systems. |
 |
| In this paper, we do an ICA based decomposition which enables us to separate text from complex backgrounds containing, reflections, shadows and specularities. For binarization, we apply a global thresholding method on the independent components of the image and that with maximum textual properties is used for extracting the foreground text. Binarization results show significant improvement in the extraction of text over other methods. Some of the word Images that we used for experiments are shown in Fig 1. The remainder of the paper is organized as follows. We discuss the general ICA model in Section II followed by the detailed binarization process in section III. Our existing method is described in Section IV.We then show the results of the proposed method on a variety of images from the ICDAR dataset in section V, followed by the conclusions and potential directions for further improvement in section VI. |
INDEPENDENT COMPONENT ANALYSIS (ICA) MODEL |
| Independent Component Analysis (ICA) has been an active research topic because of its potential applications in signal and image processing. The goal of ICA is to separateindependent source signals from the observed signals, which is assumed to be the linear mixtures of independent source components. The mathematical model of ICA is formulated by mixture processing and an explicit decomposition processing. |
| Assume there exists a set of ‘n’ unknown source signals S = {s1, s2,……sn}. The assumptions of the components {si} include mutually independent, stationary and zero mean. A set of observed signals X = {x1, x2,…..xn}, are regarded as the mixture of the source components. The most frequently considered mixing model is the linear instantaneous noise free model, which is described as: |
 |
 |
BINARIZATION PROCESS |
| A wide variety of ICA algorithms are available in the literature [11], [12]. These algorithms differ from each other on the basis of the choice of objective function and selected optimization scheme. Here we use a fast fixed point ICAalgorithm to separate out the text from complex backgroundin images. A Blind Source Separation method based on Singular Value Decomposition [10] can also be used. Fig2 shows the complete framework for the proposed method. |
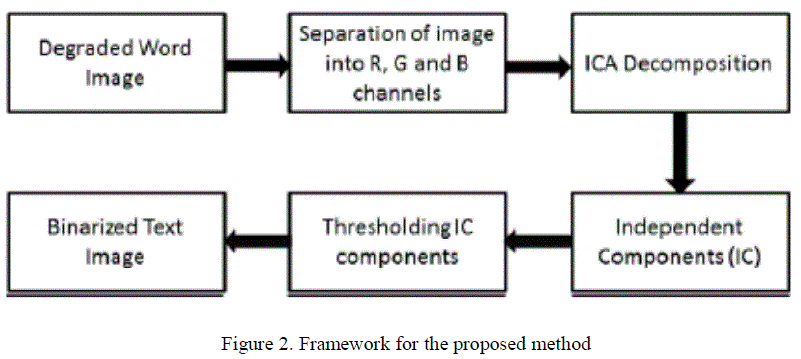 |
A. Separation Model |
| Consider the text image as a mixture of pixels from three different sources and assume it to be a noiseless instantaneous mixture. We use a single image i.e., its R, G and B channels as three observed signals. Therefore, we can define that the color intensity at each pixel from these three observed signals mix linearly to give the resultant color intensity at that pixel. Denoting these mixture images in row vector form as xr, xg and xb, the linear mixing of the sources at a particular pixel k can be expressed in matrix form as follows: |
 |
| Where X is an instantaneous linear mixture of source images at pixel k, A is the instantaneous 3x3 square mixing matrix and S is the source images which add up to form the color intensity at pixel k. The mixed images in X contain a linear combination of the source images in S. We find the mixing matrix A and sources S using fixed point ICA algorithm. From this step, we get three independent sources or components. Fig. 3 shows the background and the foreground extracted. |
 |
| Where αi denotes the number of pixels in each class, μi denotes the mean of each class, and T is the value of the potential threshold. We apply this thresholding algorithm on all the three independent components to get the binarized image. We can also apply Kittler [5] algorithm which is also a global thresholding method. To find the IC that contains the foreground text, we examine the connected components (CC) in the binarization of each IC. For each binarized image, we extract the following features from the CCs: average aspect ratio, variance of CC size, and the deviation from linearity of their centroids. A simple linear classifier is designed to separate the text and non-text classes in the above feature space. After binarization, we identify the connected components and remove non-text portions based on size and aspect ratio. In practice, we note that a simpler global thresholding scheme works well in most cases. |
EXISTING METHOD |
A. Contrast Image Construction |
| The image gradient has been widely used for edge detection and it can be used to detect the text stroke edges of the document images effectively that have a uniform document background. On the other hand, it often detects many nonstroke edges from the background of degraded document that often contains certain image variations due to noise, uneven lighting, bleed-through, etc. To extract only the stroke edges properly, the image gradient needs to be normalized to compensate the image variation within the document background. |
| The local contrast evaluated by the local image maximum and minimum is used to suppress the background variation. In particular, the difference between the local maximum and the local minimum, captures the local image difference that is similar to the traditional image gradient and a normalization factor suppresses the image variation within the document background. For image Pixels within bright regions, it will produce a large normalization factor to neutralize the numerator and accordingly result in a relatively low image contrast. For the image pixels within dark regions, it will produce a small denominator and accordingly result in a relatively high image contrast. However, this image contrast has one typical limitation that it may not handle document images with the bright text properly. This is because a weak contrast will be calculated for stroke edges of the bright text. To overcome this over-normalization problem, we combine the local image contrast with the local image gradient and derive an adaptive local image contrast as follows: |
 |
| Where Emean and Estd are the mean and standard deviation of the intensity of the detected text stroke edge pixels within a neighborhood window W, respectively.The neighborhood window should be at least larger than the stroke width in order to contain stroke edge pixels. So the size of the neighborhood window W can be set based on the stroke width of the document image under study, EW, which can be estimated from the detected stroke edges. |
EXPERIMENTAL RESULTS AND ANALYSIS |
| We used the ICDAR 2003 Robust Word Recognition Dataset [15] for our experiments. For qualitative evaluation, we selected the word images that had complex reflective, shadowed and specular background. We separate these word images into Red, Green and Blue channels assuming that these are the mixture images of the independent source images that contains the foreground (text) and background. These three images are used for extracting the foreground as described before.Text Localization and Recognition Results of proposed Binarization Method is shown in Fig. 4 below. |
 |
| We compare the performance of our method with four well known thresholding algorithms i.e., Kittler [5], Otsu [2], Niblack [9] and Sauvola [6]. We also compare with the recent method by Mishra et al [13]. It although performs well for many images but severely fails in cases of shadows, high illumination variations in the image. This poor show is likely due to fact that performance of the algorithm heavily depends on initial seeds. We show both qualitative and quantitative results of the proposed method. The qualitative results are shown in Fig. 5. We took around 50 images from the dataset and generated its ground truth images for pixel level accuracy. We use well known measures like precision, recall and F-score to compare the proposed method with different binarization methods we also use OCR accuracy to show the effectiveness of our method. Note that we are only using the subset of images that are most degraded by shadowing illumination variations, noise and specular reflections. The results of thresholding schemes are too poor for the OCR. |
 |
| The results show that the proposed method is an effective method and performs better than other methods in the case where images have complex background. Fig. 6 shows that our technique can also be applied to text image containing two different types of colored text. |
 |
| We analyze that the above methods do not work in the case where there is a complex and textured background in the images. It is not that these methods do not work at all, no single algorithm works well for all types of images. Thus we can say that our method can extract out the text embedded in complex reflective, shadowed and specular background. Our method fails in cases where foreground text and the background are of the same color. Moreover, the approach works only with color images. |
CONCLUSION |
| We have proposed an effective method to binarize text from colored scene text images with reflective, shadowed and specular background. By using a blind source separation technique followed by global thresholding, we are able to clearly separate the text portion of the image from the background. ICA decomposition enables us to separate reflections, shadows and specularities from natural scene texts so that the global thresholding methods can be applied afterwards to binarize the text image. Experimental results on ICDAR dataset demonstrate the superiority of our method over other existing methods. Possible directions for improvement of the approach includes a patch-based SVM. Classification for thresholding as well as integration of the results with a spatially aware optimization such as MRF,working with text where the foreground and background have same color is also of great interest. |
References |
|