International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| K. Hemapriya1, J. Deepa1, S. Kaviarasan1 Assistant Professor, Department of CSE, Panimalar Institute of Technology, Chennai, India |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Cloud Computing provides scalable computing and storage resources. More and more data-intensive applications are developed in this computing environment.Evaluation of cloud data center performance is a key attribute in propagation of IaaS cloud services. This evaluation is necessary to quantify the cost benefit and Quality Of Service (QoS) of Cloud services. Cloud system managers find it difficult to maintain performance data due to the huge number of parameters that need to be monitored in a cloud system. Different applications have different quality-ofservice (QoS) requirements. In this paper, we present an analytical model, based on Stochastic Reward Nets (SRNs), that is both scalable to model systems composed of thousands of resources and flexible to represent different policies and cloud-specific strategies. Several performance metrics are defined and evaluated to analyze the behavior of a Cloud data center: utilization, availability, waiting time, and responsiveness. We are also notifying the resiliency analysis to take into account the load bursts. Finally, a general approach is presented that, starting from the concept of system capacity, can help system managers to opportunely set the data center parameters under different working conditions.
Keywords |
| Cloud computing, stochastic reward nets, cloud-oriented performance metrics, resiliency, responsiveness. |
INTRODUCTION |
| Cloud computing is the use of computing resources (hardware and software) that are delivered as a service over a network (typically the Internet). The name comes from the common use of a cloud-shaped symbol as an abstraction for the complex infrastructure it contains in system diagrams. Cloud computing entrusts remote services with a user's data, software and computation. Cloud computing consists of hardware and software resources made available on the Internet as managed third-party services. These services typically provide access to advanced software applications and high-end networks of server computers. The goal of cloud computing is to apply traditional supercomputing, or high-performance computing power, normally used by military and research facilities, to perform tens of trillions of computations per second, in consumer-oriented applications such as financial portfolios, to deliver personalized information, to provide data storage or to power large, immersive computer games. The cloud computing uses networks of large groups of servers typically running low-cost consumer PC technology with specialized connections to spread data-processing chores across them. This shared IT infrastructure contains large pools of systems that are linked together. Often, virtualization techniques are used to maximize the power of cloud computing. Ondemand self-service is a consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service’s provider. Resource pooling is where the provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand.Measured service is Cloud systems automatically control and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service(e.g., storage, processing, bandwidth, and active user accounts).Capabilities can be rapidly and elastically provisioned, in some cases automatically, to quickly scale out and rapidly released to quickly scale in.The characteristics of cloud computing can be given by the Service Models. Cloud Computing comprises three different service models, namely Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS). The three service models or layer are completed by an end user layer that encapsulates the end user perspective on cloud services. If a cloud user accesses services on the infrastructure layer, for instance, she can run her own applications on the resources of a cloud infrastructure and remain responsible for the support, maintenance, and security of these applications herself. If she accesses a service on the application layer, these tasks are normally taken care of by the cloud service providers. |
| In section 2, we summarize previous work and point out main ideas that emerge from it. In section 3, proposed system is discussed. In section 4, system architechture. In section 5, experimental results are discussed. In section 6, we summarize our proposed work. |
II. PREVIOUS WORK |
| Here we review previous work,highlighting the concepts that will be exploited in our work. |
| Live virtual machine migration via asynchronous replication and state synchronization gives the design and implementation of a novel approach, namely, CR/TR-Motion,which adopts checkpointing/recovery and trace/replay technologies to provide fast, transparent VM migration for both LAN and WAN environments. With execution trace logged on the source host, a synchronization algorithm is performed to orchestrate the running source and target VMs until they reach a consistent state. CR/TR-Motion can greatly reduce the migration downtime and network bandwidth consumption. |
| The CloudSim toolkit supports modelling and creation of one or more virtual machines (VMs) on a simulated node of a Data Center, jobs, and their mapping to suitable VMs. It also allows simulation of multiple Data Centers to enable a study on federation and associated policies for migration of VMs for reliability and automatic scaling of applications. The dependability of cloud services can be analyzed with long-term performance traces from Amazon Web Services and Google App Engine, currently two of the largest commercial clouds in production. We find that the performance of about half of the cloud services we investigate exhibits yearly and daily patterns, but also that most services have periods of especially stable performance. Last, through trace-based simulation we assess the impact of the variability observed for the studied cloud services on three large-scale applications, job execution in scientific computing, virtual goods trading in social networks, and state management in social gaming. We show that the impact of performance variability depends on the application, and give evidence that performance variability can be an important factor in cloud provider selection. the Performance evaluation of cloud computing is done for the platform and not for a particular service instance. the approach focuses on NFPs (nonfunctional properties) of individual services and thereby provides a more relevant and granular information. An experimental evaluation in Amazon Elastic Compute Cloud (EC2) verified this approach. |
III. PROPOSED SYSTEM |
| In our proposed system, we present a stochastic model, based on Stochastic Reward Nets (SRNs), that exhibits the above mentioned features allowing to capture the key concepts of an IaaS cloud system. The proposed model is scalable enough to represent systems composed of thousands of resources and it makes possible to represent both physical and virtual resources exploiting cloud specific concepts such as the infrastructure elasticity. With respect to the existing literature, the innovative aspect of the present work is that a generic and comprehensive view of a cloud system is presented. Low level details, such as VM multiplexing, are easily integrated with cloud based actions such as federation, allowing to investigate different mixed strategies. An exhaustive set of performance metrics are defined regarding both the system provider (e.g., utilization) and the final users (e.g., responsiveness).To provide a fair comparison among different resource management strategies, also taking into account the system elasticity, a performance evaluation approach is described. Such an approach, based on the concept of system capacity, presents a holistic view of a cloud system and it allows system managers to study the better solution with respect to an established goal and to opportunely set the system parameters. |
IV. SYSTEM ARCHITECHTURE |
 |
| Here,we consider an IaaS cloud system composed of physical resources Job requests (in terms of VM instantiation requests) are enqueued in the system queue. once the queue limit is reached, further requests are rejected. The system queue is managed according to a ROUND ROBIN scheduling policy. When a resource is available, a job is accepted and the corresponding VM is instantiated. We assume that the instantiation time is negligible and that the service time (i.e., the time neededto execute a job) is exponentially distributed.According to the VM multiplexing technique the cloud system can provide a number of logical resources. In this case, multiple VMs can be allocated in the same physical machine (PM). The performance degradation of multiplexed VMs depends on the multiplexing technique and on the VM placement strategy. The system is able to optimally balance the load among the PMs with respect to the resources required by VMs. Cloud federation allows the system to use, in particular situations, the resources offered by other public cloud systems through a sharing and paying model. In this way, elastic capabilities can be exploited to respond to particular load conditions. Job requests can be redirected to other clouds by transferring the corresponding VM disk images through the network. A job is redirected only if it arrives when the system queue is full. A redirected job is inserted in the upload queue waiting for the VM transfer completion. There is a maximum number of concurrent redirected jobs (elasticity level). Finally the server status becomes normal. |
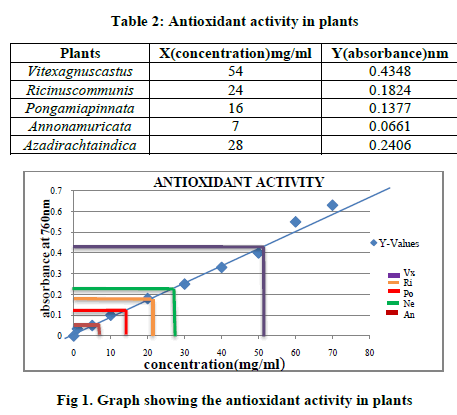
V. EXPERIMENTAL RESULTS |
| HOME PAGE: |
 |
| CHANGE PASSWORD: |
 |
| MONITOR SEVER: |
 |
| GRAPHS: |
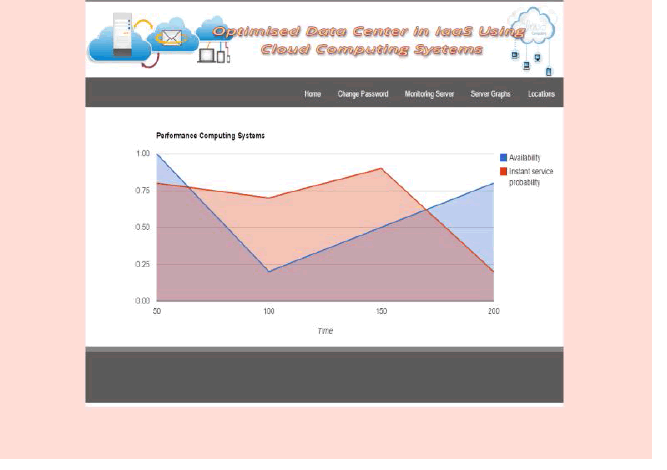 |
| LOCATIONS: |
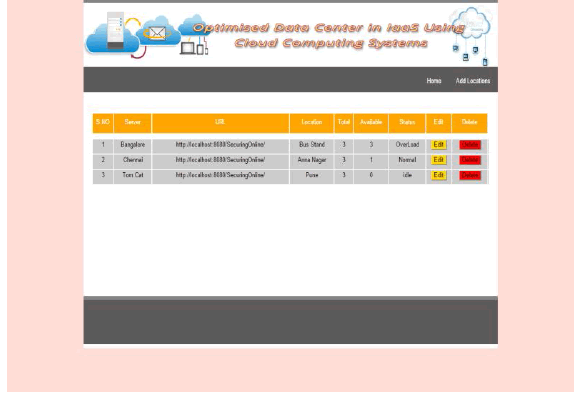 |
| EDIT LOCATIONS: |
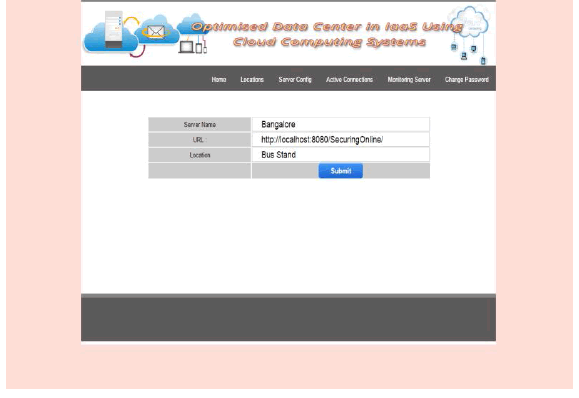 |
| ADD LOCATIONS: |
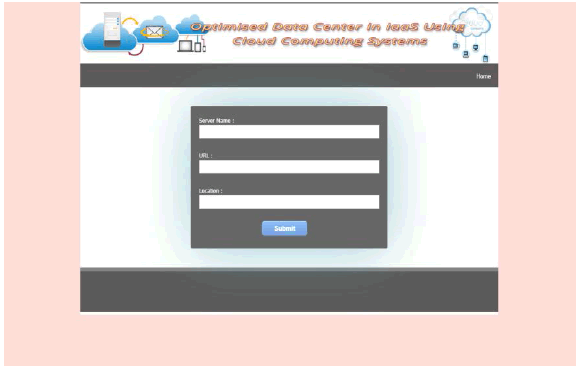 |
| ACCESS SERVER: |
 |
VI. CONCLUSION |
| In this paper, we have presented a stochastic model to evaluate the performance of an IaaS cloud system. Several performance metrics have been defined, such as availability, utilization, and responsiveness, allowing to investigate the impact of different strategies on both provider and user point-of-views. In a market-oriented area, such as the Cloud Computing, an accurate evaluation of these parameters is required in order to quantify the offered QoS and opportunely manage SLAs. Future works will include the analysis of autonomic techniques able to change on-thefly the system configuration in order to react to a change on the working conditions. We will also extend the model in order to represent PaaS and SaaS Cloud systems and to integrate the mechanisms needed to capture VM migration and data center consolidation aspects that cover a crucial role in energy saving policies. |
References |
|