Keywords
|
| VoIP, Spectral Subtraction, Discrete Wavelet Transform (DWT), Adaptive Wiener Filter |
INTRODUCTION
|
| Speech is common mode of communication in the midst of human being and also the most efficient and reliable form of exchanging information among human. Speech has been embedded into many applications like speech recognition, development of hearing aid, VoIP, mobile and other forms of personal communication. In speech communication systems to get improvement in quality of speech at low bit rate, Linear Predictive Coding (LPC), Discrete Cosine Transform (DCT) and Discrete Wavelet Transform (DWT) are used [1]. In environment undesirable noise causes undesired effects in speech signal transmission and reception. Speech enhancement techniques have been widely used for minimizing these undesirable background noises. According to specific application, the requirement of speech enhancement technique varies to increase speech quality, intelligibility and performance of speech communication devices. VoIP (voice over internet protocol) played a vital role in communication system. Echo is the problem occurs in VoIP which reduces the quality of speech signal. It is difficult to remove echo completely but it can remove to tolerable range. If we try to remove it completely then it degrades the quality of speech signal on VoIP system [2]. Speech enhancer is required to improve the quality of degraded speech in VoIP system. Fig. 1 shows the required flow of process in VoIP system for echo cancellation and speech enhancement. |
| Speech enhancement techniques are broadly classified depending on the number of microphones used in system. Single channel speech enhancement system does not use reference noise but uses voice activity detector to characterized noise statistics during non voice region. Since last five decades, various approaches for noise reduction and speech enhancements have been investigated and developed. Single channel speech enhancement techniques mostly based on transform domain, adaptive filtering and model based techniques [3]. In this paper we focus on the quantitative performance comparison of transform domain and adaptive filtering single channel speech enhancement techniques for personal communication. |
| Recent advances in CPU and multi-core hardware has provided ample amount of computational power and thus, need for today is to design the complex but yet efficient and realistic approach for noise reduction to achieve speech enhancement. There are various types of advanced speech enhancement algorithms classified in main three categories, namely; filtering/estimation based noise reduction, beam forming and active noise cancellation (ANC) techniques [4]. In this paper, work has two-fold objectives. First is to implement Spectral Subtraction, Wavelet Transform and Adaptive Wiener filtering based single channel speech enhancement techniques using Graphical User Interface (GUI) in MATLAB for personal communication. Second, we attempted to fairly evaluate and compare the objective performance of these speech enhancement techniques using performance parameters like Signal to Noise Ratio, Peak Signal to Noise Ratio, Mean Square Error, Normalised Root Mean Square Error and Average Absolute Difference. Subjective performance is also compared along three dimensions SIG, BAK and OVRL. |
| The remaining part of the paper is organized as follows: In next section II, works related to the single channel speech enhancement techniques have been presented. Section III explains the objective evaluation of WT, SS and AWF speech enhancement techniques. Section IV explains subjective evaluation using three dimensions SIG, BAK and OVRL. Section V explains the MATLAB GUI implementation of above three speech enhancement techniques. Section VI specifies the results obtained with various experiments. Finally, paper is concluded with summary of the work in section VII. |
RELATED WORK
|
| The simplest form of speech enhancement primitive is the noise reduction from the noisy speech and is applicable for single channel based speech applications. In this type of speech enhancement techniques, algorithms are either/combinely based on the model of noisy speech or/and perceptual model of speech using masking threshold. The generalized diagram of single channel enhancement technique is shown in fig. 2. |
| A. Spectral Subtraction Technique |
| Spectral subtraction technique is historically one of the first algorithms proposed for background noise reduction [5] as shown in Fig. 3 Spectral subtraction is performed by subtracting an estimate of the noise spectrum from the noisy speech spectrum as shown in Fig. 3. |
That is 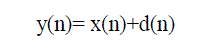 (1) (1) |
| Where y(n), x(n) and d(n) denote the noisy speech, clean speech and uncorrelated additive noise, respectively. In frequency domain it can be written as |
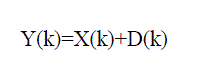 (2) (2) |
| Where „k? is index of frequency. Estimated clean speech spectrum is obtained as |
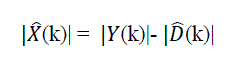 (3) (3) |
| Where ?? (k) is average magnitude of noise spectrum. |
| B. Wavelet Transform Technique |
| Spectral subtraction most widely used in single microphone algorithms for speech enhancement but it produces difficulties in pause detection due to additional relic as musical noise. DONOHA [6] in 1995, presented approach for denoising signal degraded by additive white noise using wavelet thresholding technique. Even though several papers [7, 8] were presented the application of wavelet transform for speech enhancement, but there are many issues yet to be determined for speech enhancement, where speech signals degraded by various noise sources. |
| In wavelet domain representation wavelet concentrate speech information into a few neighbouring coefficients. So as a result, taking wavelet transform of a speech signal, many coefficients will either be zero or have negligible magnitudes. Different steps involved in implementation of speech enhancement using wavelet transform are shown in Fig.4. |
| Optimal wavelet can be selected by energy conservation properties. In this paper Daubechies wavelet (dB10) is used because it is observed that it concentrate more than 96% of signal energy in the level approximation coefficients. Next step is to decompose a signal into different resolutions or frequency bands, which are carried by choosing wavelet function and determining the Discrete Wavelet Transform (DWT). Here decomposition level chosen to be at scale 5 which is adequate for processing of speech signal. Next task is to truncating small value wavelet coefficients below a threshold, hard thresholding used in this experiment. After truncating, small value coefficients are encoded efficiently with two bytes one byte indicates a sequence of zeros in wavelet transforms vector and the second byte representing the number of consecutive zeros. Further synthesizing noisy speech signal using inverse discrete wavelet transform results in enhanced speech signal. |
| C. Adaptive Wiener Filtering |
| Wiener filtering estimates noise free speech signal from that noisy speech signal corrupted by additive noise. Estimation is performed by minimizing the Mean Square Error (MSE) between the noise free signal ??(??) and its estimation ?? (n). The problem with this method is that it has fixed frequency response at all frequencies and it also required estimation of power spectral densities of noise free and noise signal before filtering. To solve this problem, M.A. Abd E-Fattah [9] presented adaptive wiener filtering approach in 2008. According to this approach enhanced speech signal of small segment stationary noisy signal can be represented as |
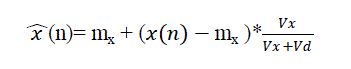 (4) (4) |
| Where mx is mean of noise free speech signal, ???? and ???? are variance of noise free speech and noise respectively. If „vx? is smaller than „vd?, input signal x(n) is attenuated due to filtering effect. Different steps involved in implementation of speech enhancement using Adaptive Wiener Filtering are shown in Fig.5. |
OBJECTIVE EVALUATION
|
| The objective comparison of three single channel speech enhancements is carried by evaluating performance of parameters such as, Mean Square Error (MSE), Normalized Mean Square Error (NRMSE), Signal to Noise Ratio (SNR), Peak Signal to Noise Ratio (PSNR) and Average Absolute Distortion (AAD). It is based on mathematical comparison of the original and processed speech signals. |
| A. Signal to Noise Ratio (SNR) |
| It is most widely used and popular method to measure the quality of speech. It is ratio of signal to noise power in decibals. |
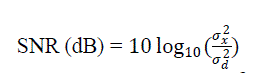 (5) (5) |
| Where σx2 is the mean square of speech signal and σd2 is the mean square difference between the original and reconstructed speech. |
| B. Peak Signal to Noise Ratio (PSNR) |
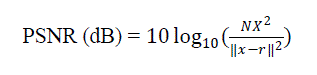 (6) (6) |
| Where N is the length of the reconstructed signal, X is the maximum absolute square value of signal x and x-r2 is the energy of the difference between the original and reconstructed signal. |
| C. Normalized Root Mean Square Error (NRMSE) |
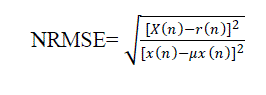 (7) (7) |
| D. Mean Square Error (MSE) and Average Absolute Distortion (AAD) |
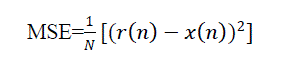 (8) (8) |
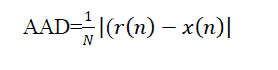 (9) (9) |
| Where N is length of input speech signal, x(n) is input speech signal and r(n) is reconstructed speech signal. |
SUBJECTIVE EVALUATION
|
| The subjective comparison of three single channel speech enhancement techniques is measured to evaluate the speech quality along three dimensions: signal distortion (SIG) in this listener rate the speech signal alone using a five point scale of signal distortion, noise distortion (BAK) where listener rate the background noise alone using five point scale of background intrusiveness and overall quality (OVRL), where listener rate the overall effect using the scale of the Mean Opinion Score (MOS) [1=bad, 2=poor, 3=fair, 4=good, 5=excellent][10]. A total of 10 listeners were recruited for the listening test between the ages 20 to 40 years and the test lasted approximately one hours. Listeners given maximum score to Wavelet Transform based single channel speech enhancement technique due to its good speech reconstruction quality. |
MATLAB GRAPHICAL USER INTERFACE IMPLEMENTATION (GUI)
|
| For better understanding MATLAB Graphical User Interface (GUI) is developed for objective performance comparison of single channel speech enhancement techniques. GUIDE command of MATLAB is used to build this interface. In figure window for development of GUI Push Buttons, Static Text, Edit Text and Axes buttons are used. After putting all items in figure window, each item is programmed in MATLAB. Fig. 6 shows how all this should be seen. |
EXPERIMENTAL RESULTS
|
| This section shows the effectiveness of our proposed work. The experimental results that concerned to our single channel speech enhancement systems were compared to Wavelet Transform (WT), Adaptive Wiener Filtering (AWF) and Spectral Subtraction (SS) methods. Test for speech enhancement were performed using uncontaminated recorded “Hello” word, which have 11020 samples, one second length, data size of 22040 bytes and PCM 11.025KHz, 16 bit Mono audio format using sound recorder of PC. This word is then contaminated with white gaussian noise type SNR of 0,-10,-20,-30,-40,-50 and -60dB to show the ability of single channel speech enhancement techniques for improving SNR in noisy speech environment for personal communication. In this paper the parameters used to compare performance of speech enhancement techniques are Signal to Noise Ratio (SNR), Peak Signal to Noise Ratio (PSNR), Mean Square Error (MSE), Normalized Mean Square Error (NRMSE) and Average Absolute Difference (AAD). |
| Fig.7 shows that WT method perform well throughout the input SNR range (-60 to 0 dB), while performance of AWF and SS remain almost same for the range -60 to -40 dB noise level. For the range -30 to 0 dB, SS method shows significant improvement in enhanced SNR value compare to AWF method. Fig. 8 shows PSNR for WT is slightly greater for the range from -60 to -25 dB compare to AWF and SS methods, while SS method shows significant improvement from -20 to 0 dB input SNR. |
| Fig. 9 shows that MSE is less for SS method compare to other methods, while Fig. 10 shows that NRMSE is less for WT compared to SS and AWF methods. |
| Fig. 11 shows that AAD for WT and SS is minimum for the range of -60dB to 0dB, while performance of AWF is poor for the range of -30 to -20 dB of input SNR. |
| From the above Table I to Table V results, it is clearly found that WT based single channel speech enhancement performed well in both clean and noisy environment. |
CONCLUSION
|
| The main objective of the speech enhancement is to bring up the performance in the presence of noise and echointerference to the performance obtained with pure speech signals, which is the ideal case. Thus, our aim was to approach the performance of single channel based speech enhancement techniques to that in the case of ideal signal. Another objective of this work is to compare objective and subjective performance of WT, AWF and SS based single channel speech enhancement techniques and the parameters used for comparison are Mean Square Error, Normalized Mean Square Error, Signal to Noise Ratio, Peak Signal to Noise Ratio and Average Absolute Distortion. Subjective evaluation also proved that Wavelet Transform based speech enhancement technique perform better due to good speech reconstruction quality. MATLAB GUI developed for speech enhancement techniques which help to be able to visualize the results obtained throughout this paper. |
ACKNOWLEDGMENT
|
| The authors thank Research Project of University of Mumbai, Mumbai, India for funding the project on “Quantitative Performance Comparison of Single Channel Speech Enhancement Techniques for Personal Communication”. |
Tables at a glance
|
 |
|
|
|
|
| Table 1 |
Table 2 |
Table 3 |
Table 4 |
Table 5 |
|
Figures at a glance
|
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
 |
 |
 |
 |
| Figure 5 |
Figure 6 |
Figure 7 |
Figure 8 |
 |
 |
 |
| Figure 9 |
Figure 10 |
Figure 11 |
|
References
|
- V. Radha, Vimala C. and M. Krrishnaveni “Comparative Analysis of Compression Techniques for Tamil Speech Datasets”, IEEEInternational Conference on Recent Trends in Information Technology (ICRTIT), 978-1-4577-0590-8/11/$26.00 © 2011 IEEE, 2011.
- P.M. Halder and A. K. M. Fazlul Haque, “Improved Echo Cancellation in VOIP”, International Journal of Advanced Computer Science and Applications(IJACSA), Vol. 2, No. 11, pp. 122-125, 2011.
- A.M. Kondoz, Digital Speech Coding for Low Bit Rate Communication Systems, John Wiley and Sons. Ltd., pp 379-405, 2007.
- Milind U. Nemade and Prof. Satish K. Shah, “Improvement in Speech Recognition Performance using Beamforming based Speech Enhancement," International Journal of Electronics Communicationand Computer Engineering (IJECCE), Vol.3, Issue 4, pp.745-751 , 2012
- Boll S. F., "Suppresion of acoustic noise in speech using spectral subtraction," IEEE Trans. Acoust. Speech, Signal Processing, vol.ASSP- 27, pp.113-120, 1979.
- Donoha D.L., "Denoising by soft thesholding," IEEE Transactions on Information Theory, vol.41, no.3, pp. 613- 627, 1995.
- Subhra Debdas, Vaishali Jagrit, Chinmay Chandrakar, and M.F. Quereshi, "Application of wavelet transform for speech processing, " International Journal of Engineering Science and Technology (IJEST), Vol.3, No.8, pp.6666-6670, 2011.
- C. Gargour, M. Gabrea, V. Ramachandran, and J. Lina, "A Short Introduction to Wavelets and Their Applications," IEEE Circuits and Systems Magazine, ISSN: 1531-636X, Vol.2, pp. 57-67, 2009.
- M.A. Abd E-Fattah, M. I. Dessouky, S. M. Diab and F. E. Abd El-samie, "Speech Enhancement using Adaptive Wiener Filtering Approach," Progress in Electromagnetic Research M, Vol.4, pp.167-184, 2008.
- D. Deepa, C. Prakarsha, and A. Shanmugam, "Single Channel Speech Enhancement using Spectral Gain Shaping method and Dereverberation for Digital Hearing Aid," International Conference on Computer Communication and Informatics(ICCCI), 978-1-4577- 1583-9/12/$26.00© 2012 IEEE, Coimbatore, India, 2012.
|