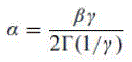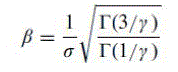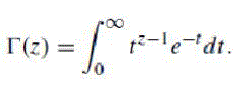- Q. Li and Z. Wang, “Reduced-reference image quality assessment using divisive-normalization-based image representation,” IEEE J. Sel. TopicsSignal Process., vol. 3, no. 2, pp. 202–211, Apr. 2009.
- J. Malo and V. Laparra, “Psychophysically tuned divisive normalization approximately factorizes the PDF of natural images,” Neural Comput.,vol. 22,no. 12, pp. 3179–3206, 2010.
- A. K. Moorthy and A. C. Bovik, “Visual importance pooling for image quality assessment,” IEEE J. Sel. Topics Signal Process., vol. 3, no. 2, pp. 193–201, Apr. 2009.
- K. Seshadrinathan and A. C. Bovik, “Motion tuned spatio-temporal quality assessment of natural videos,” IEEE Trans. Image Process., vol.19, no. 2,pp. 335–350, Feb. 2010.
- G. E. Legge and J. M. Foley, “Contrast masking in human vision,” J. Opt. Soc. Amer., vol. 70, no. 12, pp. 1458–1471, 1980.
- H. B. Barlow, “Redundancy reduction revisited,” Netw. Comput. Neural Syst., vol. 12, no. 3, pp. 241–253, 2001.
- S. Gabarda and G. Cristobal, “Blind image quality assessment through anisotroy,” J. Opt. Soc. Amer., vol. 24, no. 12, pp. B42–B51, Dec.2007.
- W. S. Geisler and J. S. Perry, “Contour statistics in natural images: Grouping across occlusions,” Visual Neurosci., vol. 26, no. 1, pp. 109–121, 2009.
- A. K. Moorthy and A. C. Bovik, “Perceptually significant spatial pooling strategies for image quality assessment,” Proc. SPIE Human Vis. Electron.Imag., vol. 7240, pp. 724012-1-–724012-11, Jan. 2009.
- A. Srivastava, A. B. Lee, E. P. Simoncelli, and S. C. Zhu, “On advances in statistical modeling of natural images,” J. Math. Imag. Vision, vol. 18, no.1, pp. 17–33, 2003.
- H. R. Sheikh, A. C. Bovik, and G. De Veciana, “An information fidelity criterion for image quality assessment using natural scene statistics,” IEEETrans. Image Process., vol. 14, no. 12, pp. 2117–2128, Dec. 2005.
- A. C. Bovik, T. S. Huang, and D. C. Munson, “A generalization of median filtering using linear combinations of order statistics,” IEEE Trans.Acoust. Speech Signal Process., vol. 31, no. 6, pp. 1342–1350, Dec. 1983.
- H. G. Longbotham and A. C. Bovik, “Theory of order statistic filters and their relationship to linear FIR filters,” IEEE Trans. Acoust. Speech SignalProcess., vol. 37, no. 2, pp. 275–287, Feb. 1989.
- K. Sharifi and A. Leon-Garcia, “Estimation of shape parameter for generalized gaussian distributions in sub band decompositions of video,” IEEETrans. Circuits Syst. Video Technol., vol. 5, no. 1, pp. 52–56, Feb. 1995.
- A. C. Bovik, M. Clark, and W. S. Geisler, “Multichannel texture analysis using localized spatial filters,” IEEE Trans. Pattern Anal. Mach. Intell., vol.12, no. 1, pp. 55–73, Jan. 1990.
- Y. Shain, A. Akerib, and R. Adar, “Associative architecture for fast DCT,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process., May 1998, pp.3109–3112.
- J. Huan, M. Parris, J. Lee, and R. F. DeMara, “Scalable FPGA-based architecture for DCT computation using dynamic partial reconfiguration,” ACMTrans. Embedded Comput. Syst., vol. 9, no. 1, pp. 1–18, Oct. 2009.
- S. Balam and D. Schonfeld, “Associative processors for video coding applications,” IEEE Trans. Circuits Syst. Video Technol., vol. 16, no. 2,pp.241–250, Feb. 2006.
- P. Duhamel, C. Guillemot, and J. C. Carlach, “A DCT chip based on a new structured and computationally efficient DCT algorithm,” in Proc. IEEEInt. Symp. Circuits Syst., May 1990, pp. 77–80.
- N. I. Cho and S. U. Lee, “Fast algorithm and implementation of 2-D discrete cosine transform,” IEEE Trans. Circuits Syst., vol. 38, no. 3, pp. 297–305, Mar. 1991.
- M. Haque, “A 2-D fast cosine transform,” IEEE Trans. Acoust. Speech Signal Process., vol. 33, no. 6, pp. 1532–1539, Dec. 1985.
- N. Bozinovic and J. Konrad, “Motion analysis in 3D DCT domain and its application to video coding,” Signal Process. Image Commun., vol.20, no.6, pp. 510–528, Jul. 2005.
- H. R. Sheikh, Z. Wang, L. Cormack, and A. C. Bovik. LIVE Image Quality Assessment Database Release 2 vOnline].Available:http://live.ece.utexas.edu/research/quality
- N. Ponomarenko, V. Lukin, A. Zelensky, K. Egiazarian, M. Carli, and F. Battisti, “TID 2008 a database for evaluation of full-reference visual qualityassessment metrics,” Adv. Modern Radioelectron., vol. 10, pp. 30–45, 2009.
- M. H. Pinson and S. Wolf, “A new standardized method for objectively measuring video quality,” IEEE Trans. Broadcast., vol. 10, no. 3, pp. 312–322, Sep. 2004.
|