International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Ms.Jyoti D.Gavade1, Mrs.Gyankamal J.Chhajed2, Ms.Kshitija A. Upadhyay3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
In this paper, we have reviewed and analysed different image retrieval systems. The purpose of this survey however, is to provide an overview of the functionality of temporary image retrieval systems in terms of technical aspects: querying, relevance feedback, features, matching measures, indexing data structures, and result presentation. We have reviewed different techniques like text based retrieval, content based retrieval, image annotation to get images captured by digital camera. The classification techniques such as k-KNN,SVM,Decision stump, Manifold Ranking, Hash Encoding Algorithm followed by a suitable relevant feedback model via cross domain learning , GMISVM , Laplacian Regularized Least Squares(LapRLS), Search Result Clustering(SRC)Algorithm , Biased Discriminative Euclidean embedding (BDEE)to refine the image retrieval result of consumer photos. After thorough study, this review also claims that most systems uses low level features and only few uses high level semantically meaningful features and the image retrieval results affect due to this semantic gap. The semantic gap is often regarded as a major problem in the field of image retrieval research. The comparative chart presents the details of different image retrieval system and addresses the factors to be considered for evaluation of results.
Keywords |
| Text based retrieval, Content based retrieval, Image annotation, Classifiers, Relevant feedback |
INTRODUCTION |
| There is lots of increasing interest in the world of digital photography. Now a day's every person has a digital camera or mobile. Every person has rights to capture photos of beautiful nature and surrounding. These captured images are not consisting of semantic concepts such as proper name like web images[3]. Person may be put a proper name to the captured image or may not be and these images are organized in folders without providing indexing. So we remove the difficulty of retrieving images from personal collections different image retrieval techniques are present as shown in fig 1. |
 |
| And also with the ever-growing number of images on the Internet, retrieving relevant images from a large collection of database images has become an important research topic. It is well known that the major problem in image retrieval is the semantic gap between the low-level features (color, texture, shape, etc.) and the high-level semantic concepts. So it is very important question, how to minimize “semantic gap” as shown in fig 2? |
 |
| Most of Proposed systems use web image database and classifiers to satisfy users demand for proper relevant image retrieval. Some of the systems used popular Wordnet onthology for automatically retrieved images which are relevant and irrelevant using inverted file method. Image annotation as the application of computer vision for retrieving images is also known as automatic image tagging or linguistic indexing. Using tagging or annotation method computer system directly assigns captioning or keywords to a digital image [5]. It is commonly used to classify images according to the high-level semantic concepts. It is generally used as an intermediate stage for TBIR image retrieval and must be performed before it because the semantic concepts are analogous to the textual terms that describe document contents[9].When a input text given by user are not present in the current set of vocabularies then user needs to perform another annotation to consumer photos. |
BACIS IDEA OF IMAGE RETRIEVAL SYSTEM |
| Let us consider the basic idea of image retrieval. General goal of image retrieval systems are: |
| ïÃâ÷ It must able to process natural language query. |
| ïÃâ÷ Search must be performed among annoted and non-annoted images and considers human visual perception. |
| ïÃâ÷ It must take account the various features of an image. |
| The images can be automatically indexed by summarizing their visual features in image retrieval systems. A feature is one of the important characteristic which captures a certain visual property of an image either globally for the entire image or locally for regions or objects. Color, texture and shape are commonly used features in systems. |
| Mapping the image pixels into the feature space is known as feature extraction. Extracted features are used to represent images for searching, indexing and browsing images in an image database. Once the features are represented as a vector it can be used to determine the similarity between images. The systems use different techniques to measure similarity. |
IMAGE RETRIEVAL SYSTEMS |
A. Bag-based ranking: |
| In this paper, Lixin Duan,Wen Li,Ivor Wai-Hang Tsang and Dong Xu proposes a novel methodology for improving web image search by bag based reranking[1].The proposed methodology used text query to get relevant images and then performed reranking using visual features. |
| The process is done as follows: |
| a) Combining of both visual and textual features, they form cluster of relevant images. Each cluster can be considering as a “bag” and the images present in bag are treating as “instances,” then apply multi-instance (MI) learning problem. |
| b) They use mi-SVM as MI learning method so that can be readily incorporated into bag-based reranking framework. While observing we know that a positive bag contains certain portion of positive instances and negative bag may also consist of positive instances. c) Finally use the generalized MI learning method. |
| c) GMI-SVM was developed to enhance retrieval performance observing the ambiguities of instances present in positive and negative bags. A bag ranking method was proposed to acquire bag annotations for GMI learning so that they performed ranking to all the bags according to the defined bag ranking score. |
| Advantages: |
| 1) The automatic bag annotation process achieves best performances as compared with existing methods of image reranking. |
| 2) GMI-SVM can achieve better performances. |
| Disadvantages |
| 1) Labels of relevant training images are quite noisy so the constraints on positive bags may not always be satisfied in this application. |
Manifold- Ranking Algorithm |
| In this paper, J. He, M. Li, H. Zhang, H. Tong, and C. Zhang proposes a novel methodology Manifold- Ranking Based Image Retrieval [2]. The proposed methodology is based on the following steps: |
| a) They propose a novel transductive learning framework for image retrieval based on a manifold ranking algorithmhere first weighted graph is formed using kNN approach and assign a positive ranking score to each query and zero to remaining points. |
| b) Then design and investigate different schemes for utilizing the positive and combination of positive, negative relevance feedback to improve the retrieval result |
| c) Finally use active learning methods to speed up the convergence to the query concepts. Advantages: |
| 1) Processing time can be greatly reduced. |
| 2) It reduced scale of weighted graph to form a small graph. |
| Disadvantages: |
| 1) It degrades the performance of Relevance feedback. |
Cross-domain Algorithm |
| In this paper Yiming Liu, Dong Xu, Member, IEEE, Ivor Wai-Hung Tsang, and Jiebo Luo, proposes a novel methodology for Textual query-based consumer photo retrieval system [3]. |
| The process can be done as: |
| a) They introduce how to retrieve consumer photo considering millions of web images with their rich textual descriptions. |
| b) They perform integration of large database and Wordnet to get relevant and irrelevant images based on textual query. After that apply classification techniques such as kNN, SVM, Decision stumps. |
| c) To refine the retrieval result of personal photos consisting of feature distribution may differ in web images and personal photos. So to better results they consider a new approach as cross-domain regularized regression. |
| Advantages: |
| 1) Images can be retrieved without using image annotation process. |
| 2) Framework is efficiently used for large scale consumer photo retrieval. |
Tag based Image Retrieval |
| In this paper Lin Chen, Dong Xu, Ivor W. Tsang, Jiebo Luo Tag-based Image Retrieval Improved by Augmented Features and Group-based Refinement [4] In this paper, they propose a new tag-based image retrieval framework to improve the retrieval performance of a group of related personal images captured by the same user within a short period of an event by considering millions of training web images and their associated rich textual descriptions. a) For any given query tag the inverted file method is employed to automatically determine the relevant and irrelevant training web images that are associated with the query tag. |
| b) Using these relevant and irrelevant web images as positive and negative training data respectively, they propose a new classification method called SVM with Augmented Features (AFSVM) to learn an adapted classifier by leveraging the pre-learned SVM classifiers of popular tags that are associated with a large number of relevant training web images. |
| c) For refinement process, they propose to use the Laplacian Regularized Least Squares (LapRLS) method to further refine the relevance scores of test photos by utilizing the visual similarity of the images within the group. |
| Advantages: |
| 1) The technique captures the geometry of the data points in the high-dimensional space. |
Tag based Image Retrieval |
| In this paper Wei Bian and Dacheng Tao presents Biased Discriminate Euclidean Embedding for Content-Based Image Retrieval has represented images by low-level visual features. Now a day’s very popular image retrieval technique is the Content-based image retrieval (CBIR) which used visual information. In this they must have to give query as an example instead of text query. It is also known as query by image content [12]. The retrieval process consist of the contents of the image such as textures, shapes,colors and other information of image itself.[3].They have designed a mapping to select the effective subspace from for separating positive samples from negative samples based on a number of observations. They have proposed the Biased Discriminative Euclidean Embedding (BDEE) which parameterizes samples in the original high-dimensional ambient space to discover the intrinsic coordinate of image low-level visual features. |
| Advantages: |
| 1) It preserves both the intraclass geometry and interclass discrimination |
| 2) It is superior to the popular relevance feedback dimensionality reduction algorithms. |
| 3) Its extension considers the unlabelled samples. |
Active Learning Support Vector Machine |
| In this paper S. Tong and E. Chang presents Support Vector Machine Active Learning for Image Retrieval Mostly CBIR systems returns semantically relevant images to the user's query image. So depending upon the application the number of techniques present in CBIR varies. But result images should all share common elements with the provided example. However as person’s point of view, it is more convenient and natural for a user to retrieve images using a query as text. The early relevance feedback method directly adjusts weights of various features. SVM-based relevance feedback methods were proposed [3][6]. Relevance feedback can be proposed in CBIR systems to recover the semantic gap. In RF search results will be improved or refine the results based on whether the results are related not related or neutral to search query then repeating the search with the new information.SVM-based relevance feedback methods were proposed [3][6]. |
| Disadvantages: |
| 1) It degrades the retrieval performance of the techniques considering limited number of feedback images. |
Auto-annotation |
| In this paper Xin-Jing Wang, Lei Zhang, Feng Jing, Wei-Ying Ma presents AnnoSearch, a novel way to annotate images using search and data mining technologies. |
| a) In this approach at least one correct keyword is compulsory to enable text-based search for semantically similar images. |
| b) Then to retrieve visually similar images content-based search is performed. Finally annotations performed from the descriptions (titles, URLs and surrounding texts) of these images. |
| c) For better efficiency and significantly speed up the content-based search process used high dimensional visual features which are mapped to hash codes. |
| Advantages: |
| 1) Annotation can be performed with unlimited vocabulary which is impossible for all existing approaches. |
ANALYSIS |
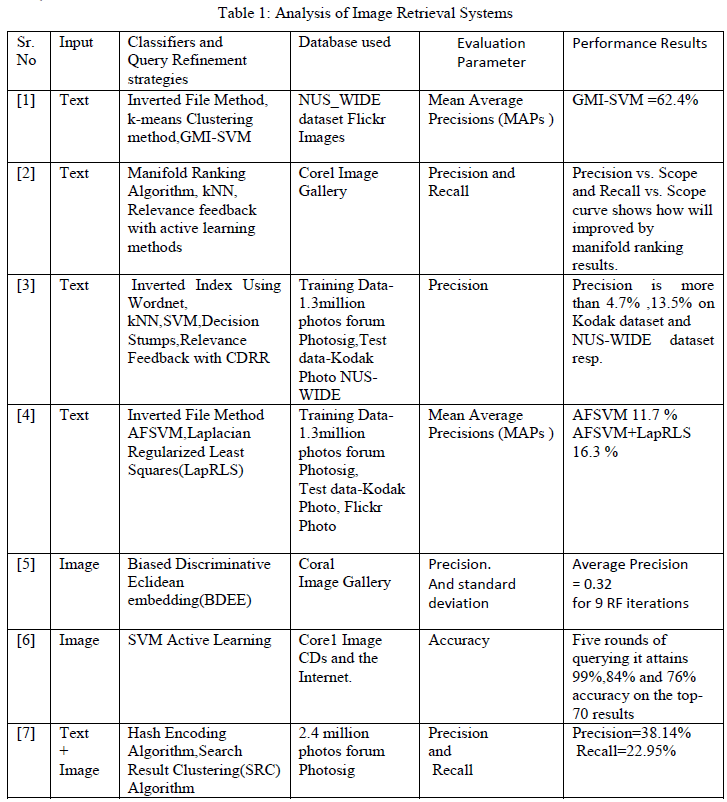
| The analysis of the seven methods will be evaluated using the parameters as Mean average precision, Standard deviation, Precision-Recall as shown in table 1. |
 |
CONCLUSION |
| In this paper we have reviewed and analysed different methods with data sets used to retrieve images capture by digital camera or mobile which do not have high level semantics concept. The parameters used for the experimental evaluation of the results are precision, recall and accuracy and Standard deviation. As considering results of different methods, we conclude that for better retrieval performance we must used the techniques to increase values of parameters like Precision-Recall, Accuracy and Standard deviation, which may lead to better results of retrieval performance. |
References |
|