International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| Ranu Dixit1 Navdeep Kaur2 M.Tech Students, Information Technology, Chandigarh Engineering College, Landran, Mohali,Punjab, India1 Faculty of Information Technology, Chandigarh Engineering College, Landran,Mohali, Punjab, India1 |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In today‟s world, Speech Recognition is very important and popular. Automatic Speech Recognition System consists of three phases: Preprocessing, Feature Extraction and Recognition. Speech recognition is the process of converting spoken words into text. In case of speech recognition the research followers are mainly using three different approaches namely Acoustic phonetic approach, Pattern recognition approach and Artificial intelligence approach. The main goal of this paper is to discuss the various techniques of speech recognition and study Hidden Markov Model of stochastic approach to develop voice based, user friendly interface software system.
Keywords |
||
| Automatic Speech Recognition (ASR), Hidden Markov Model (HMM), Feature Extraction. Algorithms, Stochastic Approach | ||
INTRODUCTION |
||
| A. Speech Recognition: Definition and Issues: Speech recognition is the process of converting an input acoustic signal (input in audio format in the form of spoken words) and recognises the various words contained in the speech. These recognised words can be the final results, which may serve as commands and control, or they may serve as input to further language processing. In simple words, speech recognition can be put together as the ability to take the audio format as input and then generate the text format from it as output. | ||
| Speech recognition [1] [2] involves different steps: | ||
| 1. Voice recording | ||
| 2. Word boundary detection | ||
| 3. Feature extraction [3] | ||
| 4. Recognition with the help of language models [4] | ||
II. SPEECH RECOGNITION APPROACHES: |
||
| Speech recognition process deal with speech variability and account for learning the relationship between specific utterance and the corresponding word or word [5].There has been steady progress in the field of speech recognition over the recent year with two trends [6].First is academic approach and second is the pragmatic, include the technology, which provides the simple low-level interaction with machine, replacing with buttons and switches. A second approach is useful now, while the former mainly make promises for the future. There are three approaches to speech recognition [7] [8] [9]. | ||
| A. Acoustic-phonetic approach [10][11][12][13] | ||
| B. Artificial Intelligence approach | ||
| C. Pattern recognition approach | ||
| A Acoustic-phonetic Approach: The earliest approaches to speech recognition were based on finding speech sounds and providing appropriate labels to these sounds. This is the basis of the acoustic phonetic approach (Hemdal and Hughes 1967), which postulates that there exist finite, distinctive phonetic units (phonemes) in spoken language and that 3these units are broadly characterized by a set of acoustics properties that are manifested in the speech signal over time. Even though, the acoustic properties of phonetic units are highly variable, both with speakers and with neighboring sounds (the so-called co articulation effect), it is assumed in the acoustic-phonetic approach that the rules governing the variability are straightforward and can be readily learned by a machine. The first step in the acoustic phonetic approach is a spectral analysis of the speech combined with a feature detection that converts the spectral measurements to a set of features that describe the broad acoustic properties of the different phonetic units. The next step is a segmentation and labeling phase in which the speech signal is segmented into stable acoustic regions, followed by attaching one or more phonetic labels to each segmented region, resulting in a phoneme lattice characterization of the speech. The last step in this approach attempts to determine a valid word (or string of words) from the phonetic label sequences produced by the segmentation to labeling. In the validation process, linguistic constraints on the task (i.e., the vocabulary, the syntax, and other semantic rules) are invoked in order to access the lexicon for word decoding based on the phoneme lattice. The acoustic phonetic approach has not been widely used in most commercial applications [14]. | ||
| B Artificial Intelligence Approach (Knowledge Based Approach): The Artificial Intelligence approach [15] is a hybrid of the acoustic phonetic approach and pattern recognition approach. In this, it exploits the ideas and concepts of Acoustic phonetic and pattern recognition methods. Knowledge based approach uses the information regarding linguistic, phonetic and spectrogram. Some speech researchers developed recognition system that used acoustic phonetic knowledge to develop classification rules for speech sounds. While template based approaches have been very effective in the design of a variety of speech recognition systems; they provided little insight about human speech processing, thereby making error analysis and knowledge-based system enhancement difficult. On the other hand, a large body of linguistic and phonetic literature provided insights and understanding to human speech processing. In its pure form, knowledge engineering design involves the direct and explicit incorporation of expert speech knowledge into a recognition system. This knowledge is usually derived from careful study of spectrograms and is incorporated using rules or procedures. Pure knowledge engineering was also motivated by the interest and research in expert systems. However, this approach had only limited success, largely due to the difficulty in quantifying expert knowledge. Another difficult problem is the integration of many levels of human knowledge phonetics, phonotactics, lexical access, syntax, semantics and pragmatics. Alternatively, combining independent and asynchronous knowledge sources optimally remains an unsolved problem. In more indirect forms, knowledge has also been used to guide the design of the models and algorithms of other techniques such as template matching and stochastic modeling. This form of knowledge application makes an important distinction between knowledge and algorithms Algorithms enable us to solve problems. Knowledge enable the algorithms to work better. This form of knowledge based system enhancement has contributed considerably to the design of all successful strategies reported. It plays an important role in the selection of a suitable input representation, the definition of units of speech, or the design of the recognition algorithm itself. | ||
| C. Pattern Recognition Approach: The pattern-matching approach (Itakura 1975; Rabiner 1989; Rabiner and Juang 1993) involves two essential steps namely, pattern training and pattern comparison. The essential feature of this approach is that it uses a well formulated mathematical framework and establishes consistent speech pattern representations, for reliable pattern comparison, from a set of labeled training samples via a formal training algorithm. A speech pattern representation can be in the form of a speech template or a statistical model (e.g., a HIDDEN MARKOV MODEL or HMM [21] [22] [23] [24] [25] [26] and can be applied to a sound (smaller than a word), a word, or a phrase. In the pattern-comparison stage of the approach, a direct comparison is made between the unknown speeches (the speech to be recognized) with each possible pattern learned in the training stage in order to determine the identity of the unknown according to the goodness of match of the patterns. The pattern-matching approach has become the predominant method for speech recognition in the last six decades [14]. In this, there exists two methods namely template approach and stochastic approach. | ||
| 1. Template Based Approach: Template based approach [15] to speech recognition have provided a family of techniques that have advanced the field considerably during the last six decades. The underlying idea is simple. A collection of prototypical speech patterns are stored as reference patterns representing the dictionary of candidate s words. Recognition is then carried out by matching an unknown spoken utterance with each of these reference templates and selecting the category of the best matching pattern. Usually templates for entire words are constructed. This has the advantage that, errors due to segmentation or classification of smaller acoustically more variable units such as phonemes can be avoided. In turn, each word must have its own full reference template; template preparation and matching become prohibitively expensive or impractical as vocabulary size increases beyond a few hundred words. One key idea in template method is to derive a typical sequences of speech frames for a pattern(a word) via some averaging procedure, and to rely on the use of local spectral distance measures to compare patterns. Another key idea is to use some form of dynamic programming to temporarily align patterns to account for differences in speaking rates across talkers as well as across repetitions of the word by the same talker. | ||
| 2. Stochastic Approach: Stochastic modeling [15] entails the use of probabilistic models to deal with uncertain or incomplete information. In speech recognition, uncertainty and incompleteness arise from many sources; for example, confusable sounds, speaker variability s, contextual effects, and homophones words. Thus, stochastic models are particularly suitable approach to speech recognition. The most popular stochastic approach today is hidden Markov modeling. A hidden Markov model is characterized by a finite state markov model and a set of output distributions. The transition parameters in the Markov chain models, temporal variabilities, while the parameters in the output distribution model, spectral variabilities. These two types of variabilites are the essence of speech recognition. Compared to template based approach, hidden Markov modeling is more general and has a firmer mathematical foundation. A template based model is simply a continuous density HMM, with identity covariance matrices and a slope constrained topology. Although templates can be trained on fewer instances, they lack the probabilistic formulation of full HMMs and typically underperforms HMMs. Compared to knowledge based approaches; HMMs [27] [28] [29] [30] [31] [32] enable easy integration of knowledge sources into a compiled architecture. A negative side effect of this is that HMMs do not provide much insight on the recognition process. As a result, it is often difficult to analyze the errors of an HMM system in an attempt to improve its performance. Nevertheless, prudent incorporation of knowledge has significantly improved HMM based systems. | ||
III. HIDDEN MARKOV MODEL |
||
| HMM is one of the key technologies developed in the 1980s, is the hidden Markov model (HMM) approach [16][17][18]. It is a doubly stochastic process which as an underlying stochastic process that is not observable (hence the term hidden), but can be observed through another stochastic process that produces a sequence of observations. Although the HMM was well known and understood in a few laboratories (primarily IBM, Institute for Defense Analysis (IDA) and Dragon Systems), it was not until widespread publication of the methods and theory of HMMs in the mid-1980s that the technique became widely applied in virtually every speech recognition research laboratory in the world. In the early 1970s, Lenny Baum of Princeton University invented a mathematical approach to recognize speech called Hidden Markov Modeling (HMM). | ||
| The HMM pattern-matching strategy was eventually adopted by each of the major companies pursuing the commercialization of speech recognition technology (SRT).The U.S. Department of Defense sponsored many practical research projects during the 70s that involved several contractors, including IBM, Dragon, AT&T, Philips and others. Progress was slow in those early years. The technique of HMM has been broadly accepted in today?s modern state-or-the art ASR systems mainly for two reasons: its capability to model the non-linear dependencies of each speech unit on the adjacent unit and a powerful set of analytical approaches provided for estimating model parameters [19][20] | ||
| A. Definition and Description of HMM: Hidden Markov Model (HMM) [33][34][35][36][37][38] [39][40] is a state machine. The states of the model are represented as nodes and the transition are represented as edges. The difference in case of HMM is that the symbol does not uniquely identify a state. The new state is determined by the symbol and the transition probabilities from the current state to a candidate state. [1] is a tutorial on HMM which shows how it can be used. Figure 1 shows a diagrammatic representation of a HMM. Nodes denoted as circles are states. O1 to O5 are observations. Observation O1 takes us to states S1. aij defines the transition probability between Si and Sj . It can be observed that the states also have self transitions. If we are at state S1 and observation O2 is observed, we can either decide to go to state S2 or stay in state S1. The decision is made depending on the probability of observation at both the states and the transition probability. | ||
| Thus HMM Model is defined as: | ||
| λ = (Q,O, A,B, π ) | ||
| Where Q is {qi} (all possible states) | ||
| O is {vi} (all possible observation) | ||
| A is {aij} where aij = P(Xt+1 = qj |Xt = qi) (transition probabilities) | ||
| B is {bi} where bi(k) = P(Ot = vk|Xt = qit) (observation probabilities of observation k at state i) | ||
| π is { π i} where π i = P(X0 = qi) (initial state probabilities) | ||
| Xt denotes the state at time t | ||
| Ot denotes the observation at time t. | ||
| B. HMM and Speech Recognition: HMM can be classified upon various criteria: | ||
| 1. Values of Occurrences – Discrete | ||
| – Continuous | ||
| 2. Dimension | ||
| – One Dimensional | ||
| – Multi Dimensional | ||
| 3. Probability density function | ||
| – Continuous density (Gaussian distribution) based | ||
| – Discrete density (Vector quantisation) based | ||
| While using HMM for recognition, we provide the occurrences to the model and it returns a number. This number is the probability with which the model could have produced the output (occurrences). In speech recognition occurrences are feature vector rather than just symbols. Hence for each occurrence, feature vector has a group of real numbers. Thus, what we need for speech recognition is a Continuous, Multi-dimensional HMM [39][40][41][42][43][44][45]. | ||
| C. Implementation: There are HMM library that were looked at: | ||
| HTK: HMM Tool Kit - is matured HMM implementation. But the license of usage does not allow redistribution of code. A C++ implementation of HMM by Prof. Dekang Lin: The problem with this implementation was that it was a discrete HMM implementation. GHMM: GHMM is a open source library for HMM. It supports both discrete and continuous HMM. But it did not have support for more than one dimension. | ||
| Continuous HMM library, which supports vector as observations, has been implemented in the project. The library uses Gaussian probability distribution function.XML file containing a specification of HMM. The sample has five states with a vector size of three The root tag in the HMM file is HMM which indicates that the file contains a HMM Model. The tag has two attributes states and vector-size indicating the number of states and the vector size of an observation for the HMM respectively. Each state consists of the outgoing edges with their probabilities. These outgoing edges are stored as transition tag inside the state. Each tag has the target state id and the probability of transition. A state also has one or more mixtures. A mixture consists of a vector of mean and a matrix of variance, one for each dimension. These mean and variance are used to calculate probability for an occurrence. The way of calculating the probability is discussed. | ||
IV. RECOGNITION USING HMM |
||
| Recognise a word using the existing models of words that we have. Sound recorder need to record the sound when it detects the presence of a word. This recorded sound is then passed through feature vector extractor model. The output of the above module is a list of features taken every 10 msec. This features are then passed to the Recognition module for recognition. The list of all the words that the system is trained for and their corresponding models are given in a file called models present in the HMMs. All models corresponding of the words are then loaded in memory. The feature vectors generated by the feature vector generator module act as the list of observation for the recognition module. Probability of generation of the observation given a model,P(O|λ) , is calculated for each of the model using find probability function. The word corresponding to the HMM [46][47][48][49][50], that gives the probability that is highest and is above the threshold, is considered to be spoken. | ||
| A. Forward Variable | ||
| Forward variable was used to find the probability of list of occurrence given a HMM. For a model with N states, probability of observation, in terms of forward variable given the model is defined as | ||
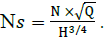 |
||
| where αt+1 is recursive defined as | ||
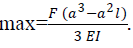 |
||
where 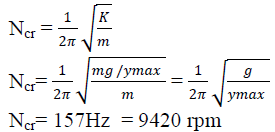 |
||
| B. Training the Model | ||
| Train command is used to train the system for a new word. The command takes at-least 3 parameters: | ||
| 1. No of states the HMM model should have N. | ||
| 2. The size of the feature vector D. | ||
| 3. One or more filenames each containing a training set. | ||
| For generating an initial HMM we take the N equally placed observations (feature vector) from the first training set. Each one is used to train a separate state. After training the states have a mean vector which is of size D. And a variance matrix of size D * D containing all zeros. Then for each of the remaining observations, we find the Euclidean distances between it and the mean vector of the states. We assign a observation to the closest state for training. The state assigned to consecutive observations are tracked to find the transitional probabilities. | ||
V. CONCLUSION |
||
| In this paper, we discussed the various techniques of speech recognition and studied Hidden Markov Model (HMM). We observed that HMM is best among all modeling technique. This study has been carried out to develop voice based, user friendly interface software system. We can use it in various applications and can take advantages as real interface. We would use it for blind and visually impaired persons as their virtual eye in future. | ||
ACKNOWLEDGEMENT |
||
| The authors remain thankful to Rajvinder Singh (H.O.D of Computer Science Engineering, CGC Landran, Mohali), for their useful discussions and suggestions during the preparation of this technical paper. | ||
Figures at a glance |
||
|
||
References |
||
|
