International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Manjuatha M B1, Pradeep kumar B.P.2, Santhosh.S.Y3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
This survey paper proposes a real time implementation for a human skeleton recognition by Kinect that can be used for vision-based human interfaces.Using of the low cost device Kinect with its SDK tool kit gives us a possibility to resolve with ease some difficult problems encounteredwhen working with conventional cameras. In particular, we are interested in a specific stream of vector extraction of twenty body-joint as a coordinate to identify skeletal structure of the human body captured by Kinect camera. The recognized gesture patterns from skeletal structure used to study various postures like stand, sit down, and lie down.In conventional systems they are bypassing so many problems when they are working in ideal conditions. The velocities and angle between the joints hitting the floor by tracking the 3D joints are discussed. In this paper different methodologies, segmentation, feature extraction, classifiers are conferred and compared.
Keywords |
| Human Computer Interaction (HCI), Human Posture Recognition (HPR), segmentation, feature extraction, software development kit (SDK), classifier. |
INTRODUCTION |
| Human motion analysis is gaining more and more attention in the field of human machine interaction. On one side, such popularity is caused by the fact that, existing devices become more sophisticated and combined with growing computational power has allowed to solve complicated problems. On the other side, recently appeared number of more affordable devices which may be used as a part of relatively inexpensive systems. Main areas of human motion analysis are surveillance, medicine, games, man-machine interface and animation. The major areas of research are human gesture recognition, motion analysis, and tracking. |
| Human motion analysis and gesture recognition have received considerable attention in recent years. Some of the works done are recognizing people by their walk, recognition of human movement using temporal of pattern recognition, reconstruction of 3D figure motion, perception ofbiological motion, automatic gait recognition. Human gesture is a non-vocal communication, used instead of verbal communication, intended to express meaning. It may be combined with the hands, arms or body, and also can be a movement of the head, face and eyes. Human gesture can be called several names, namely, human pattern, human posture, human pose, and human behavior. Human gesture recognition from video sequences has been heavily studied because of important applications to enhance monitoring of patients for fall motion detection, motion analysis in sports, and human behavior analysis. |
| The Kinect sensor is a motion sensing device. Its name is a combination of kinetic and connects. It was originally designed as a natural user interface (NUI) for the Microsoft Xbox 360 video game console to create a new control-free experience for the user where there's no more need for an input controller. The user is the controller. It enables the user to interact and controlsoftware on the Xbox 360 with gestures recognition and voice recognition. What really differentiates Kinect from other devices is its ability to capture depth. The device is composed of multiple sensors. In the middle it has a RGB camera allowing a resolution up to 1280x960 at 12 images per second. The usual used resolution is 640x480 pixels at 30 images per second maximum for colored video stream as the depth camera has a maximum resolution of 640x480 at 30 frames per second. On the far left of the device, It has the IR light (projector). It projects multiple dots which allows the final camera on the right side, the CMOS depth camera, to compute a 3D environment. The device is mounted with a motorized tilt to adjust the vertical angle. Kinect can detect up to 2 users at the same time and compute their skeletons in 3D with 20 joints representing body junctions like the feet, knees, hips, shoulders, elbows, wrists, head, etc. |
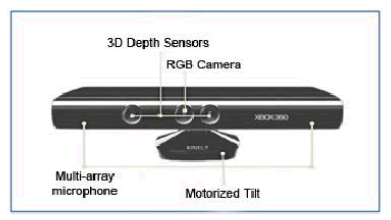 |
| Fig.1 Kinect device consists of an infrared laser projector combined with a monochrome CMOS sensor, RGB camera and a multi-array microphone |
II. RELATED RESEARCH |
| In this paper, they explore the capacity of using skeleton information provided by Kinect for human posture recognition in a context of a heath monitoring framework. They conduct 7 different experiments with 4 types of features extracted from human skeleton. The obtained results show that this device can detect with high accuracy four interested postures (lying, sitting, standing, and bending) [1].In this paper, they propose a comparison of human gesture recognition using data mining classification methods in video streaming. In particular, they are interested in a specific stream of vector of twenty body-joint positions which are representative of the human body captured by Kinect camera. The recognized gesture patterns of the study are stand, sit down, and lie down. Classification methods chosen for comparison study are back propagation neural network, support vector machine, decision tree, and naive Bayes [2]. This work proposes gesture recognition algorithm for Indian Classical Dance Style using Kinect sensor. This device generates the skeleton of human body from which twenty different junction 3- dimensional coordinates are obtained. Here they require only eleven coordinates for the proposed work. Basically six joints coordinates about right and left hands and five upper body joint coordinates are processed. A unique system of feature extraction have been used to distinguish between ‘Anger’, ‘Fear’, ‘Happiness’, ‘Sadness’ and ‘Relaxation’ [3]. A robust method for fall detection is presented based on two features: distances between human skeleton joins and the floor, and join velocity. The first feature provides an efficient solution to detect falls as the human skeleton joins close to the floor level when a person falls down [4]. This paper presents a gesture tracking method using 3D blobs and a skeleton model for interactive application. A disparity map is obtained from stereo matching based on GPGPU and they generate 3D foreground blobs using depth information. The distribution of 3D blobs is applied to determine the human position combined with the face and torso detection. The skeleton model for an upper body is fitted successively to a median axis in the area with more 3D blobs from the shoulder parts to the hands [5]. In this paper, they address the problem of human activity recognition using support vector machine (SVM) classifier. Human action recognition can be viewed as a process of detecting the actions of the individuals by monitoring their actions and environmental conditions. It is an important technology which is widely spread because of its promising applications in surveillance, health care and elderly monitoring. This is achieved by capturing the videos from depth sensor (Microsoft Kinect) through which we extract the 3D joint skeleton representation of individual as a compact representation of postures providing adequate accuracy for real-time full body tracking [6].In this paper, they present a method for human full-body pose estimation from depth data that can be obtained using Time of Flight (ToF) cameras or the Kinect device. Our approach consists of robustly detecting anatomical landmarks in the 3D data and fitting a skeleton body model using constrained inverse kinematics. Instead of relying on appearance-based features for interest point detection that can vary strongly with illumination and pose changes, we build upon a graph-based representation of the depth data that allows us to measure geodesic distances between body parts [7]. The recent popularization of real time depth sensors has diversified the potential applications of online gesture recognition to end-user natural user interface (NUI). This requires significant robustness of the gesture recognition to cope with the noisy data from the popular depth sensor, while the quality of the final NUI heavily depends on the recognition execution speed. This work introduces a method for real-time gesture recognition from a noisy skeleton stream, such as those extracted from Kinect depth sensors. Each pose is described using an angular representation of the skeleton joints. Those descriptors serve to identify key poses through a Support Vector Machine multi-class classifier, with a tailored pose kernel [8]. |
III. METHODOLOGY |
A. Algorithm-1 |
| This system consists of 3 main modules: data acquisition, data processing and feature extraction, human posture recognition. In the data acquisition module, they are capturing different types of information: color, depth and skeleton information. The data processing and feature extraction module aims at doing some processing if needed such as data normalization and at computing relevant features for posture representation. The human posture recognition module aims at learning and classifying given posture in one of the predefined classes such as lying, bending, sitting, and standing. [1] |
| Step-1:Capturing the color image, depth image. |
| Step-2:Segmenting the human posture from the depth image. |
| Step-3:For the segmented image mapping the skeleton. |
| Step-4:Tracking the skeleton |
| Step-5: Extracting the faturers from the joinis which is taken as an reference points |
| Step-6:Using SVM classifier comparing the current posture with the prviously stored posture. |
| Step-7:Recognising the posture i.e. Standing, Sitting, Lying, and Bending. |
B. Algorithm-2 |
| In this paper they are comparing the four types of classifiers and also the recognition rate obtained from each classifier are discussed. The four classifiers are namely BPNN, SVM, decision tree, and naïve Bayes. [2] |
(i) Backpropagation Neural Network (BPNN): |
| BPNN is a multilayer feed forward neural network, which uses backpropagation algorithm in its learning. They use a multiclass neural network to predict class membership of human gestures (stand, sit down, and lie down). They are applying BPNN methods to inductively construct a model of data. There are three layers (input layer, hidden layer, and output layer) with 60, 10, and 3 nodes, respectively. |
(ii) Support Vector Machine (SVM): |
| SVM is a promising new approach that can classify both linear and nonlinear data. Non-linear mapping is used to transform the training data within a higher dimension into a new dimension; linear mapping is used to search for a linear optimal line to separate hyperplanes. SVM consists of nodes used to train a support vector machine on the input data. It supports a number of different kernels (hyper tangent, polynomial, and radial basis function). The SVM learner supports multiple-class problems as well by computing the hyperplane between each class and the rest. In their study, they use SVM with polynomial kernel to classify and analyze regression of human gestures. |
(iii) Decision Tree: |
| Decision Tree is used to classify data from class label, which yields output as a flow chart-like tree structure. In this research, a decision tree algorithm called CART is used based on its popularity in data mining research literature. In this study, the decision tree classifies human gestures as a set of internal nodes (decision nodes) and leaf nodes. Each leaf node shows a class outcome label. The constructed tree branches present outcomes of human gestures (stand, sit down, and lie down). |
| iv) Naïve Bayes:Naïve Bayes is a statistical classification which predicts class membership based on conditional probabilities. The nodes in a Bayesian model are created from given training data. Each node counts the number of rows per attribute value per class for nominal attributes and calculates the Gaussian distribution for numerical attributes. |
C. Algorithm-3 |
| In this paper they have worked on recognizing five types of gestures. The SVM classifier has been used to classify the different gestures. They are ‘Anger’, ‘Fear’, ‘Happiness’, ‘Sadness’, and ‘Relaxation’. While ‘anger’ is expressed by aggressive hand movements, ‘relaxation’ shows static hand postures but kept at a definite angle, as is discussed in this paper. A total of 23 features have been extracted for each video sequence for depicting a specified gesture. Among them, eight are from both of the hands and the rest are from head and the body. The feet information has not been taken into account in this as it is not so important in conveying gestures in an Indian classical dance forms. [3] |
| Step-1: Create an initial database of skeletons for five Emotions |
| Step-2: Determine the acceleration for hand and elbow for both the hands |
| Step-3: If Acceleration for hand is greater than 70 m/s2 and for elbow 20 m/s2Then the unknown emotion is ‘Anger’. Else go to next step. |
| Step-4: Calculate the distance between spine and hand Distance is decreasing continuously |
| Step-5: Examine the angle between head, shoulder Centre and spine |
| Step-6: If Angle is decreasing continuously. Then the unknown emotion is ‘Sadness’. |
| Else Then the unknown emotion is ‘Fear’. |
| Step-7: Determine the percentage of angle between elbow, shoulder centre and wrist Percentage is greater than 90% |
| Then the unknown emotion is ‘Relaxation’ |
| Then the unknown emotion is ‘Happiness’. |
D. Algorithm-4 |
| In this paper integrates 3D floor plane recognition and 3D human skeleton joins motion capture, which is aimed at higher accurate fall detection. Here they are using a depth camera to track the 3D human skeleton join motion and it can also work in a dark room, which is suitable for all-day operation. And also they are using the distances from 3D human skeleton joins to floor plane and the join hitting velocities; it can robustly discriminate a fall from more cases such as slowly lying down on the floor.[4] |
| Step-1:To recognize the depth Kinect Sensor has been used to extract the 3D human skeleton join positions. |
| Step-2:3D Floor plane detection. |
| Step-3:Human recognition and extracting the features for skeleton recognition. |
| Step-4:Fall detection has been identified and join hitting velocities has been calculated. |
E. Algorithm-5 |
| In this paper, the skeleton model for the upper body is applied to overcome both the insufficient disparity map and the complicated color distribution problem.The face detector is based on Haar classifiers in the color image. More specifically, the skeleton model is fitted in succession to a median axis in the area that has more 3D blobs from the shoulder parts to the hands. The relative position and the color information of 3D blobs on the model are examined for tracking the gesture areas including arms and hands. Hand detection by the skin color, which is sampled in the head area, proceeds around the body and arm parts in 3D space, to solve a missed/false problem in the tracking process. Evaluating the color distributions from the hand to the elbow rather than from the order of the model fitting, allows us to improve tracking performance.[5] |
| Step-1:GPU based depth estimation and 3D blob generation. |
| Step-2:Human detection and 3D skeleton model fitting. |
| In order to detect the human being and compute his/her head location, they are applying three methods: |
| (i) face detection, |
| (ii) Torso detection, and |
| (iii) Head region estimation. |
| Step-3:Tracking and motion trajectory. |
Algorithm-6 |
| They propose a method for human activity recognition for 13 different types of activities captured through Kinect camera using SVM classifier.To achieve good results even if the person isnot present in the training set by using human skeletal joint features and they use discriminative models to achieve better accuracy rate for all activities. [6] |
| Step-1: Training the videos in depth sequence. |
| Step-2: Extracting the 3D skeleton joint information. |
| Step-3: Extracting the feature vectors from 3D skeleton joints. |
| Step-4: Classifying the extracted feature using SVM classifier. |
| Step-5: Perform the specified action. |
RESULTS |
| 1.In the first algorithm, they have analyzed the recognition of their system in two types of evaluation: offline evaluation and online evaluation. |
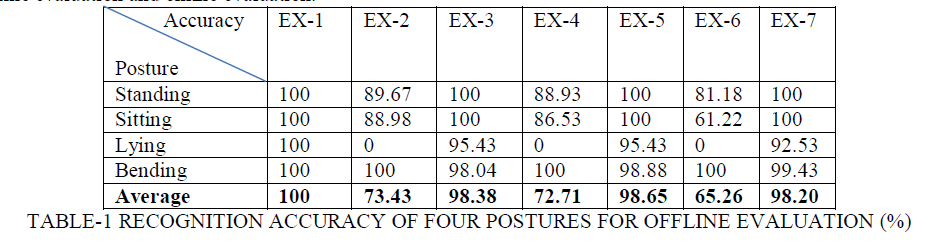 |
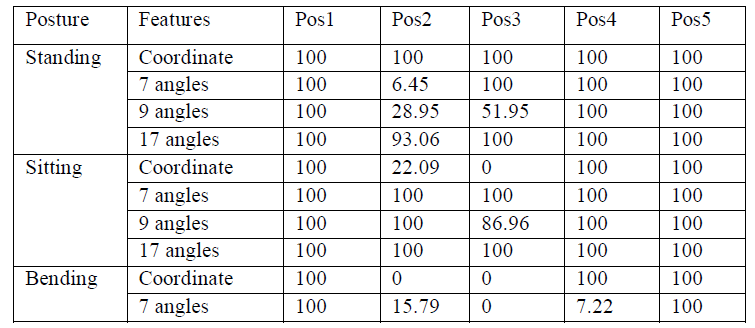 |
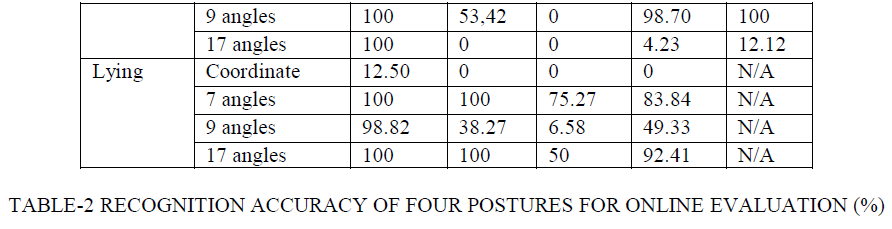 |
 |
| 3.In the third algorithm the gesture‘Anger’, the threshold values for maximum accelerationof hands and elbows is 70 m/s2 and 20 m/s2 respectively. The velocity of elbows ranges between amaximum of 1.1478 m/s and a minimum of 6.9001e-004m/s. For hands, this range lies in between 3.4501 m/sto 2.2606e-004 m/s. The gestures ‘Sadness’ and ‘Fear’gives comparatively lower values of velocity. For ‘Fear’it ranges between 0.158 m/s to 1.5827e-004 m/s while in‘Sadness’ it is 0.214 m/s to 5.4002e-004 m/s, for elbowsas well as hands.The overall accuracyobtained is 86.8% using SVM. |
| 4. In the fourth algorithm there are 4 test subjects,and their heights, ages and weights are:175.2±15 cm, 29.5±1.5 years and 72.5±7.5 kg. Their proposed method can calculate therequired distances and velocities at 30 frame/s.It correctly detected all falls. |
| 5.In the fifth algorithm the obtained results are shown in the below table |
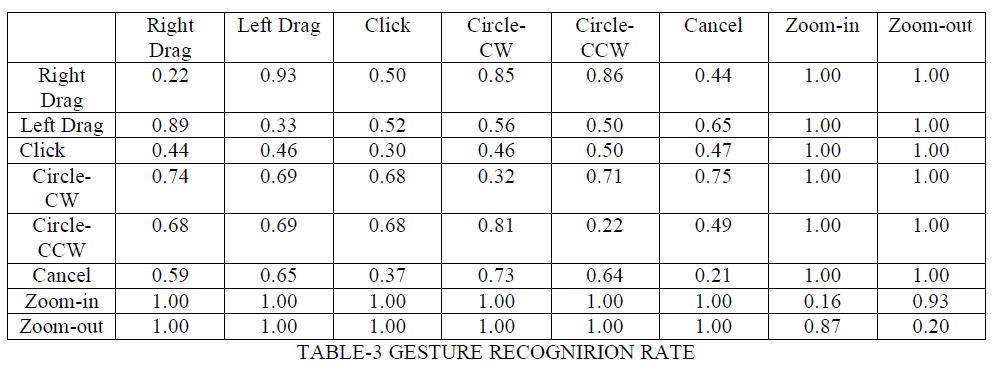 |
V. COMPARATIVE SUMMARY OF SELECTED MODEL-BASED METHODS FOR MULTIVIEW BODY POSE ESTIMATION AND TRACKING |
 |
VI. CONCLUSION |
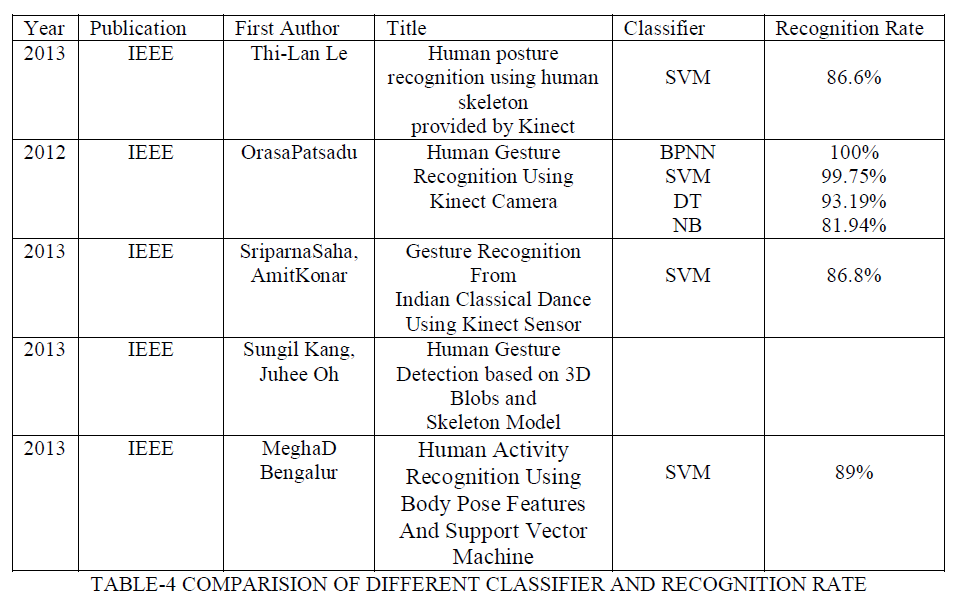
| In this paper, the concept of recognizing the different gestures/postures, methodologies, feature extraction, classifiers are discussed and compared on recognition rates obtained of a skeleton recognition using Kinect. As per our Survey different methodologies, feature extraction techniques have been compared. Among the different classifiers such as BPNN,SVM,DT,NB the BPNN has got 100% recognition apart from that SVM has 99.75% recognition rate based on the different gestures/posture either BPNN/SVM can be used.BPNN and SVM classifiers have the best recognition rate and accuracy than that of other classifiers compared in this paper.But in the referred paper they have not discussed the time response of the system. In order to obtain the good time response the system should concentrate on number of database. These databases are considered in different scenarios like ,various distances, various postures in complex and homogeneous background and different skeleton angles with respect to camera position and multi gesture environment with respect to tool used . Multi class SVM is used to get the highrecognitionrate with respect to real time environment if we are having a large database but we cannot expect good recognition rate as compared to BPNN. In BPNN good recognition rate is available but the response time is poor. This interface makes human users to be able to control smart environments by body/skeleton gestures. In future we can design our own classifier depending upon the application of our system and what are the parameters the system will going to take for feature extraction from the real time environment. |
References |
|